
- IT (1635)

오늘도 공부
Cua: Computer-Use Agents를 위한 오픈소스 본문
AI 에이전트가 코드를 생성하는 단계를 넘어, 이제는 실제 화면을 보고 버튼을 누르고 텍스트를 입력하는 단계로 넘어가고 있습니다. 문제는 여기서부터입니다. 브라우저 자동화만으로는 부족하고, 운영체제마다 입력 이벤트 처리 방식도 다르고, 화면 좌표와 해상도 이슈도 제각각입니다. “컴퓨터를 쓰는 에이전트”를 만들고 싶다면 모델보다 먼저 인프라가 필요해집니다.
Cua는 바로 그 지점을 파고드는 프로젝트입니다. 단순한 GUI 자동화 스크립트가 아니라, AI 에이전트가 macOS, Linux, Windows, Android 환경을 같은 인터페이스로 다룰 수 있게 만드는 오픈소스 인프라입니다. 저장소 기준으로 약 13.3K 스타를 기록하고 있고, 조직 설명도 “Computer-Use Agents를 위한 오픈소스 인프라”로 명확하게 잡혀 있습니다. (GitHub)
https://github.com/trycua/lume
cua/README.md at main · trycua/cua
Open-source infrastructure for Computer-Use Agents. Sandboxes, SDKs, and benchmarks to train and evaluate AI agents that can control full desktops (macOS, Linux, Windows). - trycua/cua
github.com
프로젝트 소개
Cua는 한마디로 말하면 Computer-Use Agent용 실행 환경 + 제어 API + 벤치마크 + 운영도구를 묶은 플랫폼입니다. README의 핵심 문구도 분명합니다. 화면을 보고, 클릭하고, 작업을 자율적으로 수행하는 에이전트를 만들 수 있고, VM이든 컨테이너든 관계없이 하나의 API로 다룰 수 있다는 점이 중심 가치입니다. (GitHub)
이 프로젝트가 흥미로운 이유는 “에이전트 프레임워크” 하나로 끝나지 않기 때문입니다. 저장소는 크게 이런 묶음으로 이해하면 됩니다.
- cua: 샌드박스를 만들고 제어하는 핵심 SDK
- cuabot: 코딩 에이전트나 GUI 워크플로를 샌드박스 안에서 실행하는 CLI
- cua-bench: OSWorld, ScreenSpot, Windows Arena 같은 벤치마크와 RL 환경
- cua-computer-server: 스크린샷, 클릭, 키보드 입력 같은 저수준 제어 서버
- lume: Apple Silicon에서 macOS/Linux VM을 거의 네이티브에 가깝게 돌리는 가상화 계층
- som: 스크린샷에서 UI 요소를 찾는 시각적 grounding 컴포넌트 (GitHub)
즉, Cua는 “에이전트가 컴퓨터를 사용하게 만드는 코드”만 제공하는 것이 아니라, 실행 환경과 평가 체계까지 포함한 운영 가능한 스택에 가깝습니다.
왜 이 프로젝트가 등장했을까
기존 자동화 생태계는 크게 두 갈래였습니다.
첫째는 Playwright나 Selenium 같은 브라우저 자동화입니다. 이 방식은 웹에는 강하지만, 데스크톱 앱·OS 설정·파일 탐색기·복합 워크플로 같은 영역으로 가면 한계가 분명합니다.
둘째는 RPA나 OS별 GUI 자동화 도구입니다. 이것도 마우스와 키보드는 제어할 수 있지만, 보통은 운영체제 종속성이 강하고, 에이전트가 재현 가능한 환경에서 학습·평가·배포되도록 만드는 데까지는 잘 이어지지 않습니다.
Cua가 겨냥하는 문제는 바로 이 사이입니다.
“LLM이 실제 컴퓨터를 쓰게 하려면, 입력 장치 제어만으로는 부족하고, 일관된 런타임·샌드박스·벤치마크·시각 grounding이 함께 있어야 한다.”
README만 봐도 이 철학이 드러납니다. 같은 API로 Linux, macOS, Windows, Android를 다루고, 클라우드와 로컬을 가리지 않으며, 벤치마크와 샌드박스 관리 도구가 별도 패키지로 묶여 있습니다. 이건 단순한 라이브러리 설계가 아니라 에이전트 인프라 설계입니다. (GitHub)
Cua가 해결하는 핵심 문제
1. 운영체제별 차이를 API 뒤로 숨긴다
가장 중요한 포인트는 이 부분입니다.
README 예제에서 Sandbox.ephemeral(Image.linux())만 macos(), windows(), android()로 바꾸면 같은 방식으로 실행할 수 있습니다. 즉, 에이전트 로직은 “어떤 OS인지”보다 “지금 보이는 화면에서 무엇을 할지”에 집중할 수 있습니다. 로컬에서는 QEMU 기반으로, 클라우드에서는 Cua 런타임으로 다룰 수 있게 설계되어 있습니다. (GitHub)
from cua import Sandbox, Image
async with Sandbox.ephemeral(Image.windows()) as sb:
screenshot = await sb.screenshot()
await sb.mouse.click(240, 180)
await sb.keyboard.type("Hello from Cua")
이 추상화가 중요한 이유는, Computer-Use Agent의 정책 모델은 보통 “스크린샷 → 추론 → 액션” 루프를 따르기 때문입니다. 여기서 실행 환경이 매번 달라지면 에이전트 품질이 흔들립니다. Cua는 그 런타임 차이를 줄여 줍니다.
2. 컴퓨터 제어를 저수준 서버로 분리한다
cua-computer-server는 사실상 Cua의 드라이버 계층입니다. 이 서버는 HTTP/WebSocket 인터페이스와 MCP over HTTP를 동시에 제공하고, 스크린샷, 클릭, 더블클릭, 이동, 드래그, 스크롤, 타이핑, 핫키 등 40개 이상의 도구를 노출합니다. (GitHub)
이 구조의 장점은 명확합니다.
에이전트는 직접 OS별 입력 드라이버를 붙잡을 필요가 없습니다. 대신 “도구 호출”이라는 일관된 방식으로 컴퓨터를 제어합니다. Claude Code 같은 도구와 MCP로 연결할 수 있는 것도 이 때문입니다. 즉, Cua는 단순 SDK가 아니라 에이전트 도구 서버로도 쓸 수 있습니다. (GitHub)
3. 화면 좌표 문제를 실전적으로 다룬다
실제 GUI 에이전트를 만들다 보면 가장 먼저 맞닥뜨리는 문제가 좌표 불일치입니다. Retina 디스플레이, VM 해상도, 렌더링 스케일이 섞이면 “모델이 본 좌표”와 “실제 클릭 좌표”가 어긋나기 쉽습니다.
Cua 컴퓨터 서버는 --width, --height 플래그로 타깃 해상도를 지정하면 스크린샷 리사이즈, 클릭 좌표 스케일링, 커서 좌표 보고를 일관되게 맞춰 줍니다. 이건 README 속 한 줄짜리 옵션처럼 보이지만, 실전에서는 에이전트 안정성에 매우 큰 영향을 줍니다. (GitHub)
4. 평가 환경까지 내장한다
Computer-Use Agent는 “데모”를 만드는 것과 “반복 가능하게 평가”하는 것이 완전히 다른 문제입니다.
Cua는 cua-bench를 통해 OSWorld, ScreenSpot, Windows Arena, 커스텀 태스크를 대상으로 에이전트를 평가할 수 있고, trajectory export도 지원합니다. 즉, 단순 테스트가 아니라 훈련 데이터/강화학습/회귀 검증으로 연결될 수 있는 구조입니다. (GitHub)
5. Apple Silicon을 적극적으로 활용한다
Lume는 Apple의 Virtualization Framework를 활용해 Apple Silicon 위에서 macOS/Linux VM을 거의 네이티브에 가깝게 다루는 계층입니다. 여기에 som은 Apple Silicon의 MPS를 활용해 YOLO 기반 아이콘 탐지와 EasyOCR 기반 텍스트 인식을 가속합니다. (GitHub)
이 조합은 매우 현실적입니다.
지금 많은 개발자들이 M-series Mac을 메인 머신으로 쓰고 있기 때문에, “로컬에서 빠르게 컴퓨터-사용 에이전트를 실험하고 싶은” 요구와 정확히 맞아떨어집니다.
핵심 기능 분석
1. Any OS Sandbox
Cua의 중심은 샌드박스입니다. 컨테이너, VM, 각종 이미지 위에 에이전트를 올리고, 스크린샷/마우스/키보드/셸을 공통 API로 제어합니다. 특히 README에선 Linux container, Linux VM, macOS, Windows, Android, 그리고 BYOI(.qcow2, .iso)까지 언급합니다. (GitHub)
이건 단순 호환성 자랑이 아닙니다.
개발자 입장에서는 “같은 에이전트를 고객 환경에 가깝게 재현”할 수 있다는 뜻입니다.
예를 들어 이런 시나리오가 가능합니다.
- 사내 ERP가 Windows 앱인 경우 → Windows 샌드박스
- 브라우저 + 리눅스 워크플로 → Linux 컨테이너/VM
- macOS 네이티브 앱 자동화 → macOS VM
- 모바일 앱 흐름 점검 → Android 환경
2. CuaBot
cuabot은 개발자 경험 측면에서 꽤 인상적입니다. README 설명대로라면, Claude Code나 OpenClaw 같은 에이전트를 샌드박스 안에서 돌릴 수 있고, GUI 워크플로 자체를 직접 실행하는 도구로도 사용할 수 있습니다. H.265, 공유 클립보드, 오디오까지 언급되는 걸 보면 “테스트용 데스크톱 스트리밍 환경”을 꽤 의식한 설계입니다. (GitHub)
즉, CuaBot은 단순 명령 실행기가 아니라 다음과 같은 역할을 합니다.
- 개발 중 에이전트 실험
- 사람이 샌드박스를 직접 보면서 디버깅
- 기존 코딩 에이전트에 컴퓨터 사용 능력 부여
- GUI 워크플로 재현
예시는 이렇게 이해하면 됩니다.
npx cuabot
cuabot claude
cuabot chromium
cuabot --screenshot
cuabot --type "로그인 테스트 시작"
cuabot --click 320 420
3. Computer Server + MCP
개인적으로 Cua에서 가장 “아키텍처적으로 잘 잡혀 있다”고 느껴지는 부분입니다.
에이전트 세계에서는 도구 사용이 중요합니다. 그런데 GUI 제어 도구는 대부분 앱 내부 API나 OS 훅에 강하게 묶여 있습니다. Cua는 이를 서버로 분리해 HTTP/WebSocket과 MCP 인터페이스로 노출합니다. 그래서 LLM 에이전트는 컴퓨터를 하나의 외부 툴처럼 다룰 수 있습니다. (GitHub)
예를 들면, 모델은 이런 식의 루프를 돌게 됩니다.
- 현재 화면을 캡처한다.
- 클릭 가능한 요소를 추론한다.
- computer_click이나 computer_type 같은 도구를 호출한다.
- 결과 화면을 다시 본다.
이 패턴은 다양한 에이전트 프레임워크와 잘 맞습니다.
4. Visual Grounding(SOM)
스크린샷 기반 에이전트의 난점은 “어디를 눌러야 하는지”를 모델이 정확히 이해하기 어렵다는 점입니다. Cua의 som 패키지는 이 문제를 보완합니다. YOLO 기반 아이콘 검출과 OCR을 결합해 UI 요소를 찾고, 하드웨어에 따라 MPS → CUDA → CPU로 자동 선택합니다. (GitHub)
이게 의미하는 바는 단순합니다.
- 모델이 순수 픽셀만 보고 추론하는 부담을 줄일 수 있고
- 아이콘, 버튼, 텍스트 필드, 메뉴 항목 같은 요소를 구조화할 수 있으며
- 디버깅 시 “왜 이 좌표를 눌렀는지” 설명 가능성이 올라갑니다
즉, som은 Cua를 단순 입력 자동화 도구가 아니라 지각 가능한 에이전트 런타임으로 끌어올리는 조각입니다.
5. Benchmark & RL Environment
cua-bench는 이 프로젝트를 “그럴듯한 자동화 툴”에서 “연구/제품용 인프라”로 바꿔 주는 부분입니다. OSWorld, ScreenSpot, Windows Arena 같은 벤치마크를 공식 README에서 전면에 내세우고 있고, trajectory export까지 언급합니다. (GitHub)
이 구조가 중요한 이유는 세 가지입니다.
첫째, 모델 업그레이드 전후를 비교할 수 있습니다.
둘째, 실패 사례를 데이터셋으로 다시 축적할 수 있습니다.
셋째, 데모 성공률이 아니라 재현 가능한 성능으로 팀 내 합의를 만들 수 있습니다.
프로젝트 아키텍처 분석
Cua를 아키텍처 레벨에서 단순화하면 다음과 같이 볼 수 있습니다.
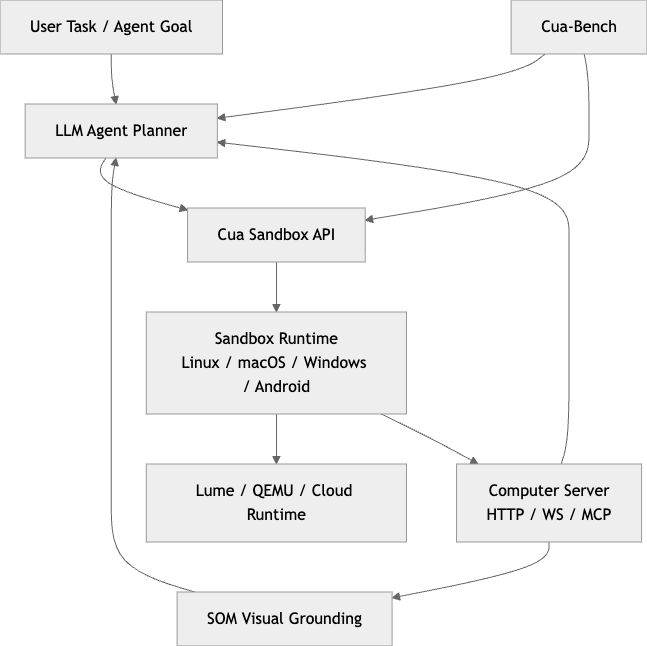
이 흐름을 개발자 관점으로 풀어보면 이렇습니다.
에이전트는 목표를 받고, 샌드박스를 하나 띄웁니다. 샌드박스 내부에는 컴퓨터 제어 드라이버가 있고, 필요하면 시각 grounding 모듈이 스크린샷을 분석합니다. 에이전트는 그 결과를 바탕으로 클릭, 타이핑, 드래그 같은 액션을 수행합니다. 그리고 같은 구조를 벤치마크 환경에 연결해 반복 평가합니다. (GitHub)
핵심은 추론 계층과 실행 계층이 느슨하게 분리되어 있다는 점입니다.
그래서 에이전트 모델을 바꾸더라도 샌드박스/평가 체계를 그대로 유지할 수 있습니다.
실제로 어떻게 동작하는가
가장 기본적인 사용 흐름은 README 예제만 봐도 충분히 읽힙니다.
from cua import Sandbox, Image
async with Sandbox.ephemeral(Image.linux()) as sb:
result = await sb.shell.run("echo hello")
screenshot = await sb.screenshot()
await sb.mouse.click(100, 200)
await sb.keyboard.type("Hello from Cua!")
여기서 중요한 건 세 가지입니다. (GitHub)
첫째, 샌드박스가 ephemeral입니다.
실험이 끝나면 버릴 수 있어 재현성과 격리가 좋습니다.
둘째, 셸과 GUI 제어가 한 객체 아래에 모여 있습니다.
즉, 브라우저 자동화와 CLI 자동화가 따로 노는 것이 아니라 하나의 태스크로 섞을 수 있습니다.
셋째, 운영체제 변경 비용이 낮습니다.
이미지 타입만 바꾸면 되기 때문에 “에이전트 로직” 자체는 더 높은 수준에 둘 수 있습니다.
예를 들어 로그인 테스트용 에이전트를 만든다고 해보겠습니다.
from cua import Sandbox, Image
async def login_flow():
async with Sandbox.ephemeral(Image.windows()) as sb:
await sb.shell.run("start chrome https://internal.example.com")
await sb.mouse.click(460, 390) # 아이디 입력창
await sb.keyboard.type("tester@example.com")
await sb.mouse.click(460, 450) # 비밀번호 입력창
await sb.keyboard.type("secret-password")
await sb.mouse.click(520, 520) # 로그인 버튼
return await sb.screenshot()
물론 실전에서는 고정 좌표보다 grounding이나 OCR, 혹은 모델 추론 루프를 섞는 게 더 안전합니다. 그래도 Cua가 어떤 문제를 푸는지 보여주기엔 충분한 예시입니다.
개발자가 주목해야 할 설계 포인트
샌드박스가 먼저고, 에이전트는 그 위에 올라간다
많은 프로젝트가 “모델이 똑똑하다”에 집중하지만, Cua는 “모델이 행동할 환경”을 먼저 정리합니다. 이 관점은 실전에서 매우 중요합니다. 모델이 아무리 좋아도 환경이 불안정하면 성공률은 떨어집니다.
로컬 실험과 운영 환경의 간극을 줄인다
Apple Silicon에서 Lume로 macOS/Linux VM을 띄우고, 동일한 API로 Windows나 Android까지 확장하는 구조는 “내 로컬 Mac에서 실험한 것이 배포 환경에서도 비슷하게 작동”하게 만들려는 방향으로 읽힙니다. (GitHub)
평가 체계가 이미 포함돼 있다
이건 팀 단위 도입에서 특히 중요합니다.
“한 번 성공했다”가 아니라 “이번 주 빌드에서 성능이 6% 떨어졌다”를 말할 수 있어야 합니다. cua-bench는 그 기반을 제공합니다. (GitHub)
MCP 친화적이다
/mcp 엔드포인트를 제공한다는 건, 앞으로 더 많은 코딩 에이전트와 워크플로 오케스트레이터에 쉽게 붙을 가능성이 크다는 뜻입니다. Cua는 독립 생태계라기보다, 에이전트 툴 체인에 편입되기 쉬운 인프라입니다. (GitHub)
언제 사용하면 좋은가
Cua는 모든 자동화 문제에 필요한 도구는 아닙니다. 하지만 아래 상황에서는 상당히 잘 맞습니다.
브라우저 자동화만으로 안 되는 경우
웹 페이지뿐 아니라 파일 탐색기, OS 설정, 데스크톱 앱, 인증 창, 다운로드 대화상자까지 포함된 흐름이라면 Cua 쪽이 더 자연스럽습니다.
멀티 OS 에이전트를 실험해야 하는 경우
동일 태스크를 Windows와 macOS에서 모두 검증해야 하거나, Android까지 포함해야 한다면 API 일관성이 큰 장점이 됩니다. (GitHub)
연구와 제품 개발을 동시에 해야 하는 경우
벤치마크와 trajectory export가 있기 때문에, 데모 제작과 평가 자동화를 따로 만들지 않아도 됩니다. 이건 팀 생산성에 직접 연결됩니다. (GitHub)
Apple Silicon 기반 개발 환경을 적극 활용하고 싶은 경우
M-series Mac을 쓰는 팀이라면 Lume와 SOM의 최적화 혜택이 꽤 매력적입니다. 특히 로컬 실험 속도가 중요할 때 더 그렇습니다. (GitHub)
아쉬운 점도 있다
좋은 프로젝트지만 냉정하게 볼 부분도 있습니다.
첫째, 실제 성공률은 결국 모델 품질과 grounding 전략에 크게 좌우됩니다. Cua가 인프라를 잘 정리해도, 복잡한 GUI 추론은 여전히 어려운 문제입니다.
둘째, 크로스플랫폼 추상화는 강력하지만, 각 OS의 세부 동작 차이를 완전히 없애 주진 않습니다. 특히 해상도, 권한, 앱별 포커스 이슈는 실전에서 계속 튀어나옵니다. 그래서 computer-server의 해상도 스케일링 같은 장치가 중요합니다. (GitHub)
셋째, 이 프로젝트는 단순 라이브러리보다 범위가 넓습니다. 즉, 도입 시 “SDK만 쓰겠다”가 아니라 “샌드박스와 평가 체계까지 어디까지 가져갈지”를 먼저 정해야 합니다.
총평
Cua는 요즘 유행하는 “컴퓨터를 쓰는 AI 에이전트”를 진짜 제품/연구 환경으로 끌고 가기 위해 필요한 것들을 꽤 잘 모아 둔 프로젝트입니다.
핵심은 세 가지입니다.
하나의 API로 여러 OS를 다룰 수 있고,
에이전트가 사용할 저수준 제어 서버가 있으며,
평가와 반복 실험을 위한 벤치마크 체계가 함께 있다.
즉, Cua는 단순한 자동화 라이브러리가 아니라 Computer-Use Agent 운영체제에 가까운 오픈소스 스택입니다. 특히 macOS, Linux, Windows, Android를 함께 보고 있는 팀, 그리고 데모를 넘어서 평가 가능한 에이전트 시스템을 만들고 싶은 팀에게 매우 흥미로운 선택지입니다. (GitHub)
'AI' 카테고리의 다른 글
| Sherlock: 사용자명 하나로 SNS 모든 계정 AI로 추적 (0) | 2026.03.31 |
|---|---|
| AgentDB: Node.js 프로젝트 안에서 바로 쓰는 문서형 DB (1) | 2026.03.31 |
| 🚪 Claude Code의 숨겨진 15가지 기능 (0) | 2026.03.30 |
| Open Agent Platform: LangGraph 에이전트를 “앱처럼” 만들고 운영하게 만든 실험 (0) | 2026.03.30 |
| OpenBB: 금융 데이터를 하나의 API로 통합하는 오픈소스 데이터 플랫폼 (0) | 2026.03.30 |