
- IT (1735)

오늘도 공부
OpenBB: 금융 데이터를 하나의 API로 통합하는 오픈소스 데이터 플랫폼 본문
AI 에이전트가 숫자를 읽고, 분석가가 대시보드를 만들고, 퀀트가 파이썬 코드로 시계열 데이터를 다루는 시대다. 문제는 늘 같다. 데이터는 많지만 인터페이스가 제각각이라는 점이다. 공급자마다 인증 방식이 다르고, 응답 스키마가 다르고, 심지어 같은 “주가 히스토리”도 필드 이름과 파라미터가 다르다. OpenBB는 이 지점을 정면으로 겨냥한다. 이 프로젝트는 단순한 금융 라이브러리가 아니라, 금융 데이터를 한 번 연결해서 여러 실행 표면에서 재사용하게 만드는 데이터 플랫폼으로 진화했다. (GitHub)
예전에는 OpenBB를 “오픈소스 금융 터미널” 정도로 이해해도 크게 틀리지 않았다. 하지만 지금의 저장소를 보면 방향이 훨씬 분명하다. OpenBB가 강조하는 것은 터미널 UI가 아니라 Open Data Platform이고, 이 플랫폼은 Python, CLI, REST API, Workspace, Excel, MCP 서버까지 이어지는 공통 인프라 레이어로 동작한다. 즉, 이 저장소의 핵심은 화면이 아니라 표준화된 데이터 접근 계층이다. (GitHub)
OpenBB/README.md at develop · OpenBB-finance/OpenBB
Financial data platform for analysts, quants and AI agents. - OpenBB-finance/OpenBB
github.com
프로젝트 소개
OpenBB는 금융 데이터 플랫폼을 만들기 위한 오픈소스 툴셋이다. 공식 설명 그대로 보면, 공개 데이터·상용 데이터·사내 데이터를 하나의 레이어에 통합해 AI 코파일럿, 리서치 대시보드, 파이썬 환경, REST API 같은 하위 애플리케이션에서 재사용하도록 설계되어 있다. 저장소 메타데이터 기준으로도 이 프로젝트는 2026년 3월 시점에 6만 개가 넘는 GitHub star를 보유하고 있고, 회사는 2021년부터 오픈 분석 솔루션을 구축해 왔다고 밝히고 있다. (GitHub)
기술 스택은 상당히 현대적이다. 아키텍처 문서에 따르면 핵심 패키지인 openbb-core는 FastAPI, Uvicorn, Pandas, Pydantic, Requests/AIOHTTP, WebSockets를 기반으로 한다. 이 조합만 봐도 프로젝트의 정체성이 드러난다. 단순 데이터 수집 스크립트가 아니라, 검증 가능한 모델 + 비동기 호출 + API 제공까지 고려한 백엔드 프레임워크에 가깝다. (OpenBB 문서)
또 하나 중요한 점은 OpenBB가 거대한 모놀리스처럼 보이지만 실제로는 확장 패키지들의 집합이라는 사실이다. openbb 메타 패키지는 openbb-core, openbb-platform-api와 함께 openbb-yfinance, openbb-equity, openbb-economy, openbb-news, openbb-fred, openbb-sec 등 다수의 공식 확장을 의존성으로 포함한다. 여기에 Alpha Vantage, CBOE, Nasdaq, Seeking Alpha 같은 커뮤니티/옵션 확장도 얹을 수 있다. 저장소를 보면 “한 제품”이라기보다 금융 데이터 운영체제에 가까운 패키지 생태계라고 보는 편이 정확하다. (GitHub)
라이선스도 체크할 필요가 있다. 저장소와 개별 provider 패키지 메타데이터는 AGPL-3.0 계열 라이선스를 사용하고 있다. 사내 서비스에 묶어 배포하거나 서버 형태로 운영하려는 팀이라면, 기술 구조뿐 아니라 라이선스 검토도 함께 해야 한다. (GitHub)
왜 이 프로젝트가 등장했을까
OpenBB가 등장한 배경은 단순하다. 금융 데이터는 원래부터 파편화되어 있었다. 주가, 재무제표, ETF holdings, 거시경제, 뉴스, 옵션, SEC 문서, 정부 데이터까지 각각 다른 API와 인증 방식을 갖는다. 개발자는 공급자별 SDK를 따로 익혀야 하고, 데이터 분석 코드는 벤더 종속적으로 쌓인다. OpenBB는 이런 환경에서 “단일하고 통합된 금융 API”를 만들겠다는 목표를 명확하게 내세운다. 공식 블로그에서도 이를 금융 데이터를 위한 오픈소스 “protocol”에 가깝게 설명하고 있다. (OpenBB)
이 접근의 핵심은 벤더를 숨기는 것이 아니라 벤더 차이를 표준 모델 뒤로 밀어 넣는 것이다. 예를 들어 사용자는 obb.equity.price.historical() 같은 동일한 호출 패턴을 유지하면서 내부적으로 yfinance, FMP, Polygon, Tiingo 등 서로 다른 공급자를 선택할 수 있다. 즉, OpenBB는 공급자들을 없애는 것이 아니라, 공급자 위에 공통 추상화 계층을 만드는 방식으로 문제를 푼다. (GitHub)
이게 왜 중요할까. 금융 데이터 제품은 시간이 갈수록 한 공급자로는 부족해지기 때문이다. 무료 공급자는 범위가 좁고, 상용 공급자는 비용이 높고, 특정 국가·자산군은 로컬 공급자가 더 강하다. 결국 실무에서는 멀티벤더 전략이 필요해진다. OpenBB는 바로 그 현실을 반영해서 “connect once, consume everywhere”를 전면에 내세운다. 한 번 붙여 놓으면 Python뿐 아니라 API, Workspace, Excel, MCP까지 같은 구조를 재사용할 수 있다. (GitHub)
이 저장소를 보면 보이는 핵심 방향성
저장소 README만 보면 “금융 데이터를 가져오는 파이썬 라이브러리”처럼 보일 수 있다. 하지만 구조를 따라가 보면 더 큰 그림이 있다.
첫째, OpenBB는 Python SDK만 만드는 프로젝트가 아니다. 공식 문서는 Python 인터페이스, CLI, REST API, MCP 서버, Workspace 백엔드로 이어지는 다중 인터페이스 전략을 분명히 설명한다. 최근 릴리스에서도 MCP 서버 설정 확장, API 쪽 메타데이터 개선, Workspace 앱 연결 같은 변화가 계속 보인다. 즉, 이 저장소는 “라이브러리”보다는 데이터 플랫폼 엔진이다. (OpenBB 문서)
둘째, OpenBB는 정적 자산을 빌드하는 SDK라는 점도 독특하다. 문서에 따르면 Python 인터페이스는 설치된 확장 목록을 기반으로 정적 자산을 빌드하고, 필요 시 openbb-build 명령으로 다시 생성한다. 이건 동적으로 모든 걸 리플렉션하는 구조보다, 사용자 환경에 맞는 인터페이스를 “컴파일”해 두는 쪽에 가깝다. 확장성이 큰 대신 런타임 제어와 초기화 순서를 꽤 신경 쓴 설계다. (OpenBB 문서)
셋째, OpenBB는 확장 가능한 표준 모델 시스템을 중심으로 설계됐다. 같은 엔드포인트라도 provider별로 입력 차이와 응답 차이가 있는데, 이를 QueryParams, Data, Fetcher, Provider, Router, OBBject라는 계층으로 정리한다. 이 구조 덕분에 “사용자에게 보이는 명령”과 “실제 공급자별 구현”을 깔끔하게 분리할 수 있다. (OpenBB 문서)
핵심 기능
1) 하나의 명령으로 여러 금융 데이터 공급자를 교체할 수 있다
OpenBB의 가장 직관적인 장점은 공통 API 표면이다. 예를 들어 주가 히스토리 조회라는 개념은 동일하지만, 내부 공급자는 여러 개가 될 수 있다. 실무에서 이건 매우 큰 장점이다. PoC 단계에서는 무료 공급자를 쓰고, 운영 단계에서는 상용 공급자로 갈아타는 식의 전환 비용을 낮출 수 있기 때문이다. (OpenBB 문서)
from openbb import obb
# 동일한 모델을 기준으로 공급자만 바꿔가며 호출
aapl_yf = obb.equity.price.historical(
symbol="AAPL",
start_date="2025-01-01",
provider="yfinance",
)
aapl_fmp = obb.equity.price.historical(
symbol="AAPL",
start_date="2025-01-01",
provider="fmp",
)
df = aapl_yf.to_dataframe()
print(df.head())
이 코드의 좋은 점은 “벤더별 SDK 문법”이 아니라 “도메인 개념” 중심으로 읽힌다는 것이다. equity.price.historical이라는 이름만으로도 엔드포인트 의미가 분명하다.
2) Python, API, CLI, MCP를 하나의 아키텍처로 묶는다
많은 오픈소스 데이터 프로젝트는 파이썬 사용성은 좋지만, API나 AI 에이전트 통합으로 가면 별도 서비스가 필요해진다. OpenBB는 처음부터 FastAPI 기반 구조를 깔고 들어가기 때문에, Python 함수와 REST API가 같은 모델과 로직을 공유한다. 공식 문서도 Python 인터페이스와 REST API가 공통 핵심 로직을 사용한다고 설명한다. (OpenBB 문서)
여기에 MCP 서버까지 얹을 수 있다는 점이 최근 OpenBB를 더 흥미롭게 만든다. openbb-mcp-server는 REST API 엔드포인트를 MCP 프로토콜로 노출해 LLM 에이전트가 툴처럼 탐색·선택하게 만든다. 릴리스 노트에서도 MCP 도구 설정과 OpenAPI 메타데이터 강화가 계속 추가되고 있다. 금융 데이터를 AI 에이전트의 툴체인에 안전하게 붙이고 싶은 팀이라면 이 부분이 꽤 매력적이다. (OpenBB 문서)
# Python SDK
pip install openbb
# API 서버/Workspace 백엔드 쪽 확장
openbb-api
# MCP 서버 실행
openbb-mcp
3) 확장 중심 설계로 기능 추가가 자연스럽다
OpenBB 문서를 보면 provider 확장은 독립 패키지로 설치·제거 가능하고, fetcher는 router와 무관하게 개별 실행도 가능하다. 즉, 새 데이터 공급자 추가는 코어를 뜯어고치는 작업이 아니라 확장 패키지를 추가하는 일에 가깝다. 이건 규모가 커질수록 중요해진다. 새로운 벤더를 붙일 때 전체 시스템에 미치는 영향 범위를 줄일 수 있기 때문이다. (OpenBB 문서)
# Fetcher는 Provider/Router 없이도 독립적으로 실행 가능한 구조를 갖는다
results = await SomeFetcher.fetch_data({"symbol": "AAPL"}, {})
이 설계는 특히 사내 데이터 소스 통합에 유리하다. 외부 벤더뿐 아니라 내부 데이터 API도 OpenBB식 provider로 감싸면, 상위 레이어에서는 같은 패턴으로 소비할 수 있다.
4) 결과 객체가 단순 dict가 아니라 “후처리 가능한 응답 객체”다
OpenBB의 응답은 OBBject라는 표준 객체로 감싸진다. 이 객체는 results, provider, warnings, extra 같은 메타데이터를 포함하고, to_dataframe(), to_dict(), to_numpy(), to_polars() 같은 변환 메서드를 제공한다. 단순히 JSON을 리턴하는 수준에서 끝나지 않고, 분석 파이프라인으로 바로 넘기기 좋은 형태를 기본 제공하는 셈이다. (OpenBB 문서)
from openbb import obb
output = obb.equity.price.historical("AAPL")
df = output.to_dataframe()
records = output.to_dict()
이 구조는 개발자 경험 측면에서 매우 실용적이다. API 응답 파싱용 보일러플레이트가 줄고, 메타데이터를 함께 들고 다니기 쉬워진다.
프로젝트 아키텍처 분석
OpenBB를 이해하려면, 화면이나 CLI 메뉴보다 명령이 어떻게 실행되는지를 먼저 봐야 한다. 이 저장소의 핵심 흐름은 대략 다음과 같다. (OpenBB 문서)
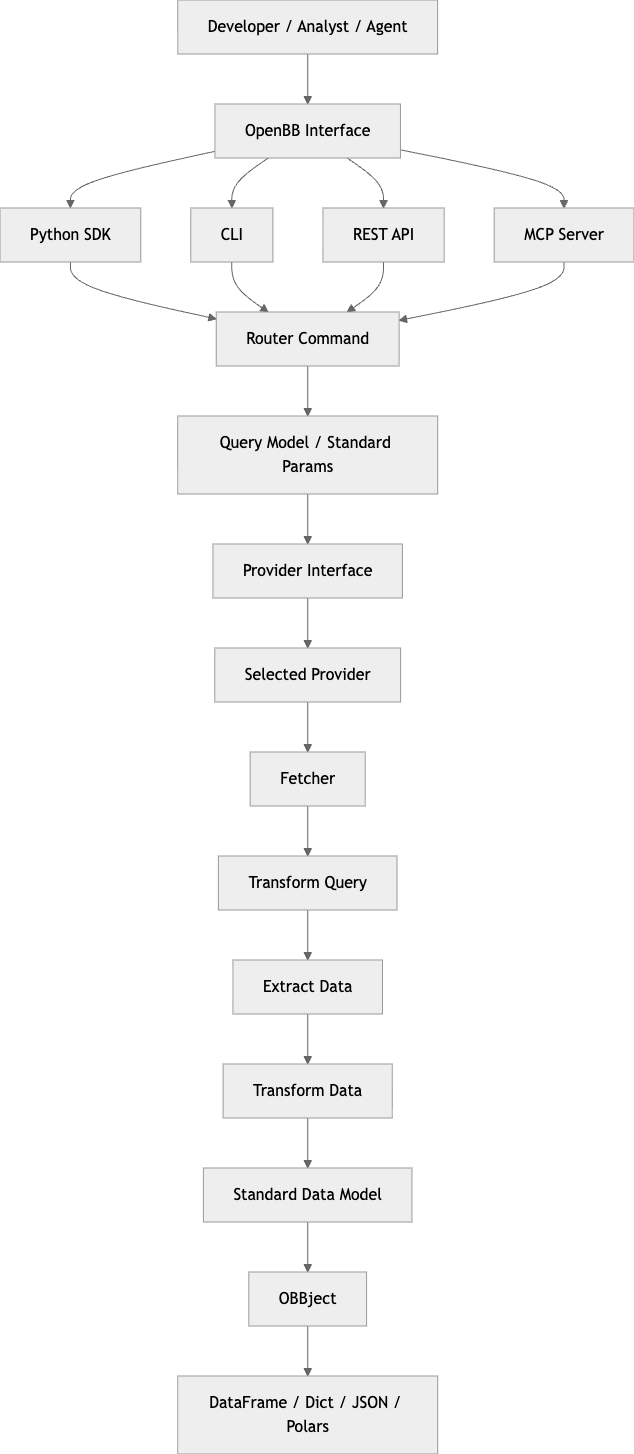
이 흐름에서 가장 중요한 컴포넌트는 다섯 개다.
Router
Router는 사용자에게 보이는 명령을 정의하는 레이어다. 예를 들어 equity/profile, equity/price/historical 같은 엔드포인트는 router에 정의된다. 공식 설명에서도 router는 openbb-core와 provider 사이의 중간 계층으로 소개된다. 즉, 도메인별 API 표면을 정의하는 곳이다. (OpenBB)
Provider Interface
Provider Interface는 설치된 provider 확장들을 매핑해 주는 싱글턴이다. 사용자가 provider="yfinance"를 넣으면, 어떤 fetcher를 써야 하는지 이 계층이 결정한다. 쉽게 말해 router가 “무슨 데이터를 원하나”를 정의한다면, provider interface는 “그걸 어느 공급자에게 물어볼까”를 결정한다. (OpenBB 문서)
Fetcher
Fetcher는 OpenBB 아키텍처의 핵심 실행 단위다. 공식 문서가 강조하는 패턴은 TET, 즉 Transform → Extract → Transform이다. 먼저 공통 파라미터를 provider 전용 쿼리로 바꾸고, 외부 데이터 소스에서 원본 데이터를 가져오고, 마지막으로 OpenBB 표준 데이터 모델로 변환한다. 이 단계 분리가 아주 중요하다. 공급자별로 제각각인 스키마를 이 마지막 transform에서 흡수하기 때문이다. (OpenBB 문서)
class SomeFetcher(Fetcher[SomeQueryParams, list[SomeData]]):
require_credentials = False
@staticmethod
def transform_query(params):
...
@staticmethod
async def aextract_data(query, credentials, **kwargs):
...
@staticmethod
def transform_data(query, data, **kwargs):
...
QueryParams / Data
QueryParams는 입력을 표준화하는 모델이고, Data는 출력을 표준화하는 모델이다. provider마다 ticker, symbol, begin, start_date가 뒤섞이는 문제를 alias와 schema 메타데이터로 흡수한다. 이 계층이 있기에 상위 API는 가능한 한 일관된 파라미터 이름을 유지할 수 있다. (OpenBB 문서)
OBBject
실행 결과는 OBBject로 감싸진다. 이 객체는 단순 결과 목록뿐 아니라 경고, provider 정보, 추가 메타데이터를 담고 다양한 포맷 변환 메서드를 제공한다. 프레임워크 수준에서 응답 계약을 강제하는 역할이라고 보면 된다. (OpenBB 문서)
저장소를 실제 서비스 관점에서 해석해 보면
개발자 입장에서 OpenBB의 가장 큰 미덕은 서비스 경계가 명확하다는 점이다.
첫 번째 경계는 도메인 경계다. equity, economy, etf, news, fixedincome처럼 금융 도메인 기준으로 router가 나뉜다. 이건 사용성뿐 아니라 팀 분업에도 좋다. 주식/거시/ETF/뉴스 팀이 각자 확장을 발전시키기 쉽다. 저장소 의존성 목록만 봐도 이 도메인 확장이 독립 패키지로 운영된다는 점이 명확하다. (GitHub)
두 번째 경계는 공급자 경계다. 같은 엔드포인트를 여러 provider가 먹일 수 있다. 이건 벤더 장애, 비용, 라이선스, 지역 데이터 커버리지 이슈에 대응하기 좋은 구조다. 예를 들어 무료 yfinance로 개발을 시작하고, 정확도·지연시간·SLA가 중요해지면 Polygon이나 FMP 같은 상용 데이터로 교체하는 식의 전략이 가능하다. (OpenBB 문서)
세 번째 경계는 인터페이스 경계다. 같은 코어 로직을 Python, API, CLI, MCP로 노출할 수 있다. 이건 특히 조직 내 데이터 플랫폼 팀에게 중요하다. 퀀트는 Python SDK를 쓰고, 프론트엔드 팀은 REST API를 쓰고, AI 팀은 MCP를 쓸 수 있기 때문이다. 하나의 데이터 계약을 여러 소비자에게 배포하는 구조다. (GitHub)
개발자가 실제로 어떻게 쓰게 될까
1) 파이썬 기반 리서치 워크플로
가장 기본적인 사용법은 파이썬에서 obb를 불러오는 것이다. README도 pip install openbb 후 from openbb import obb를 시작점으로 제시한다. 결과를 바로 DataFrame으로 바꿀 수 있어 Jupyter, 백테스트, 리포트 생성 파이프라인에 잘 맞는다. (GitHub)
from openbb import obb
prices = obb.equity.price.historical(
symbol="MSFT",
start_date="2024-01-01",
provider="yfinance",
)
df = prices.to_dataframe()
returns = df["close"].pct_change().dropna()
print(returns.describe())
2) 사내 API 백엔드
OpenBB는 FastAPI 기반이기 때문에, 내부 분석 플랫폼이나 대시보드에 붙일 데이터 백엔드로도 적합하다. 문서에는 openbb-api와 Uvicorn 설정, FastAPI 앱 변환 방식이 따로 정리되어 있다. 즉, “노트북용 라이브러리”에서 끝나는 게 아니라, 서비스형 데이터 레이어로도 바로 이어진다. (OpenBB 문서)
from fastapi import FastAPI
from openbb import obb
app = FastAPI()
@app.get("/stocks/{symbol}/history")
def get_history(symbol: str):
result = obb.equity.price.historical(
symbol=symbol,
start_date="2025-01-01",
provider="yfinance",
)
return result.to_dict()
3) AI 에이전트용 금융 툴 서버
이 부분이 최근 OpenBB의 차별점이다. OpenBB는 MCP 서버를 통해 LLM 에이전트가 금융 데이터 툴을 동적으로 탐색하고 선택할 수 있게 한다. 검색형 에이전트, 애널리스트 코파일럿, 리서치 어시스턴트 같은 제품을 만들 때 굉장히 자연스러운 조합이다. 특히 공급자 수가 많고 엔드포인트가 방대한 금융 데이터 분야에서는, 필요한 툴만 활성화하는 구조가 유용하다. (OpenBB 문서)
openbb-mcp
OpenBB가 잘한 설계 포인트
가장 인상적인 부분은 표준화와 확장성 사이의 균형이다. 보통 표준화에 집중하면 확장성이 떨어지고, 확장성에 집중하면 인터페이스가 흐트러진다. OpenBB는 router와 provider를 분리하고, fetcher에 TET 패턴을 강제하면서 이 둘을 꽤 잘 묶어냈다. 표준 모델을 유지하되, 공급자별 특수성은 내부 변환 단계로 격리한다. (OpenBB 문서)
또 하나는 플랫폼화 전략이 명확하다는 점이다. 단순 라이브러리라면 Python DX만 좋아도 된다. 하지만 OpenBB는 처음부터 Workspace, Excel, REST, MCP까지 염두에 두고 있다. 그래서 저장소가 커 보이는 대신, “왜 이런 추상화가 필요한가”가 분명하다. 단일 인터페이스만 생각했다면 이렇게까지 router/provider/obbject 구조를 밀어붙일 이유가 없다. (GitHub)
아쉬운 점도 있다
물론 이 구조가 항상 가벼운 것은 아니다. 문서에 따르면 Python 인터페이스는 정적 자산 빌드 과정을 가지며, 초기 import도 수백 MB 메모리를 쓸 수 있다. 즉, 작은 스크립트 하나만 돌리는 개발자에게는 다소 무거울 수 있다. OpenBB는 “범용 금융 데이터 플랫폼”이라는 목표를 택한 만큼, 단순한 단일 벤더 SDK보다 복잡성이 높다. (OpenBB 문서)
또한 공급자 추상화는 강력하지만, 금융 데이터 특성상 모든 벤더 차이를 완전히 없애지는 못한다. 어떤 provider는 intraday 간격이 제한적이고, 어떤 provider는 adjustment 방식이나 symbol 규칙이 다르다. OpenBB는 이 차이를 많이 흡수하지만, 실무에서는 여전히 provider별 기능 커버리지와 제약을 확인해야 한다. 문서의 데이터 모델 페이지가 provider별 파라미터 차이를 상세히 나누는 이유도 여기에 있다. (OpenBB 문서)
언제 사용하면 좋은가
OpenBB는 이런 상황에서 특히 좋다.
여러 금융 데이터 공급자를 하나의 코드베이스에서 다뤄야 할 때. 무료 공급자와 상용 공급자를 병행해야 할 때. 파이썬 노트북에서 시작한 데이터 접근 로직을 API나 대시보드 백엔드, AI 에이전트 툴 서버로 확장하고 싶을 때. 혹은 사내 고유 데이터를 OpenBB 스타일의 확장으로 감싸서 기존 분석 워크플로에 붙이고 싶을 때다. 이런 요구가 있다면 OpenBB는 단순히 편한 라이브러리가 아니라 아키텍처적으로 맞는 선택지가 된다. (OpenBB)
반대로, 특정 벤더 하나만 짧게 쓰는 작은 스크립트라면 OpenBB가 과할 수도 있다. 이 프로젝트는 “간단한 REST 래퍼”가 아니라 “금융 데이터 플랫폼 프레임워크”이기 때문이다. 플랫폼을 원하면 매우 강력하고, 단순 SDK를 원하면 다소 무거울 수 있다. (OpenBB 문서)
마무리
OpenBB를 한 문장으로 정리하면 이렇다.
OpenBB는 금융 데이터를 가져오는 도구가 아니라, 금융 데이터를 표준화해서 Python·API·AI 에이전트까지 연결하는 오픈소스 플랫폼이다. (GitHub)
이 저장소를 자세히 보면, 왜 최근 AI 시대와 잘 맞물리는지도 보인다. 에이전트는 결국 좋은 툴과 안정적인 데이터 인터페이스가 필요하다. OpenBB는 그 지점에서 금융 데이터를 위한 “툴 친화적 백엔드”가 되려 한다. Fetcher, Provider, Router, OBBject로 이어지는 구조는 조금 복잡해 보이지만, 바로 그 복잡성 덕분에 다양한 데이터 공급자와 실행 표면을 하나의 모델로 묶어낼 수 있다. 개발자 관점에서 보면, 이 프로젝트의 진짜 가치는 기능 개수보다 확장 가능한 데이터 계약에 있다. (OpenBB 문서)
'AI' 카테고리의 다른 글
| 🚪 Claude Code의 숨겨진 15가지 기능 (0) | 2026.03.30 |
|---|---|
| Open Agent Platform: LangGraph 에이전트를 “앱처럼” 만들고 운영하게 만든 실험 (0) | 2026.03.30 |
| ClawTeam: 혼자 일하던 AI Agent를 “팀”으로 바꾸는 멀티 에이전트 CLI (0) | 2026.03.30 |
| 📌 AI 영상 캐릭터 고정 완전 정리 (실전 구조) (0) | 2026.03.30 |
| pi-autoresearch: AI 코딩 에이전트를 “실험 반복 엔진”으로 바꾸는 방법 (0) | 2026.03.30 |