
- IT (1635)

오늘도 공부
AgentDB: Node.js 프로젝트 안에서 바로 쓰는 문서형 DB 본문
AI 에이전트와 로컬 툴링이 늘어나면서, 개발자들은 점점 더 자주 이런 선택지 앞에 섭니다. “그냥 SQLite 붙일까?”, “Mongo 띄울까?”, “아니면 JSON 파일로 버틸까?” 그런데 이 셋 사이 어딘가를 정확히 노린 프로젝트가 하나 있습니다. 서버 없이, 런타임 의존성 없이, Node.js 프로젝트 안에서 바로 쓰는 문서형 DB. AgentDB는 바로 그 지점을 겨냥합니다. (GitHub)
이 저장소를 자세히 보면, 단순히 “작은 DB 하나 만들었다” 수준이 아닙니다. 작성자는 바이너리 파일 포맷, 레코드 단위 AES-256-GCM 암호화, WAL 기반 크래시 복구, CRC32 무결성 검증, 필드 인덱스, TTL, 스키마 검증, 백업/복구, 마이그레이션까지 직접 구현했습니다. 그리고 이 모든 걸 Node.js + TypeScript, 그것도 런타임 zero dependency라는 제약 안에서 밀어붙였습니다. (GitHub)
GitHub - IsaacOdeimor/agentdb: Lightweight embedded document database for Node.js
Lightweight embedded document database for Node.js - IsaacOdeimor/agentdb
github.com
AgentDB는 어떤 프로젝트인가
AgentDB는 IsaacOdeimor가 공개한 경량 임베디드 문서 데이터베이스입니다. README에서 스스로를 “Node.js 프로젝트 안에 들어가는 self-contained database”로 설명하고 있고, 실제로도 별도 서버나 Docker 없이 특정 폴더를 데이터 디렉터리로 지정해 .agdb 파일과 .wal 파일을 직접 관리하는 구조입니다. (GitHub)
핵심 포지션은 아주 분명합니다.
- SQLite처럼 프로세스 안에 임베드
- MongoDB처럼 JSON 문서 모델
- 여기에 내장 암호화와 crash safety
- 그리고 서버 없는 운영 모델
즉, “작은 앱용 장난감 DB”라기보다, 로컬 에이전트, CLI 도구, 데스크톱 앱, 백엔드 사이드카 저장소, 민감 데이터 캐시 같은 시나리오를 겨냥한 스토리지 엔진에 가깝습니다. README도 SQLite·MongoDB·plain JSON과 비교하면서 이 위치를 명확히 잡고 있습니다. (GitHub)
기술 스택도 깔끔합니다. 패키지는 ESM 기반이고, 엔진 요구사항은 Node.js 18 이상입니다. package.json을 보면 런타임 의존성은 없고 개발 의존성으로 TypeScript, tsx, vitest, Node 타입만 사용합니다. “zero deps”라는 설명이 마케팅 문구만은 아니라는 뜻입니다. (GitHub)
왜 이런 프로젝트가 등장했을까
이 프로젝트가 겨냥하는 문제는 사실 꽤 현실적입니다.
첫째, JSON 파일은 시작은 쉽지만 끝이 어렵습니다. 동시 접근 제어가 없고, 부분 업데이트가 번거롭고, 장애 복구도 취약합니다. 둘째, MongoDB는 강력하지만 너무 무겁습니다. 로컬 툴이나 단일 프로세스 앱에 서버 프로세스를 얹는 순간 운영 복잡도가 급격히 올라갑니다. 셋째, SQLite는 훌륭하지만 문서 모델과 내장 암호화 경험이 바로 오지는 않습니다. AgentDB는 이 빈칸을 “JSON 문서 중심 + 임베디드 + 암호화 내장”으로 채우려는 시도입니다. 이 의도는 README의 포지셔닝과 기능 비교표에서 분명하게 드러납니다. (GitHub)
특히 AI/Agent 시대에 이런 접근이 눈에 띄는 이유가 있습니다. 에이전트 런타임은 종종 다음 조건을 동시에 요구합니다.
- 빠르게 붙일 수 있어야 하고
- 로컬 상태를 저장해야 하며
- 민감 정보가 섞이고
- 갑작스러운 종료에서도 복구돼야 하고
- 배포가 단순해야 합니다
AgentDB는 정확히 여기에 맞춰져 있습니다. README의 “SQLite, but for JSON documents — with encryption built in”이라는 표현이 이 프로젝트의 정체성을 가장 잘 보여줍니다. (GitHub)
이 저장소를 보고 느껴지는 현재 상태
이건 꽤 중요합니다. AgentDB는 아이디어만 있는 README 저장소가 아닙니다. src 아래에 엔진, WAL, 인덱서, 스키마, aggregation, cursor, migration, backup 모듈이 분리되어 있고, tests 아래에도 aggregation, collection, compression, crc32, cursor, database, encryption, engine, wal 테스트 파일이 각각 존재합니다. 저장소 구조만 봐도 작성자가 “DB처럼 보이는 라이브러리”가 아니라 실제 스토리지 계층으로 설계하려 했다는 걸 알 수 있습니다. (GitHub)
다만 아직 초기 단계 티도 납니다. README에는 npm 패키지 공개 예정이라고 적혀 있고, 현재는 저장소를 clone해서 src/에서 직접 import 하라고 안내합니다. package.json의 repository URL도 placeholder 상태라, 배포와 패키징 경험은 아직 다듬는 중으로 보는 게 맞습니다. (GitHub)
핵심 기능 1: 파일 기반이지만 JSON 파일 수준을 넘어선다
AgentDB의 데이터 파일은 단순한 텍스트 JSON이 아닙니다. README에 따르면 .agdb는 32바이트 헤더를 가진 바이너리 포맷이고, 레코드마다 CRC32 체크섬이 붙습니다. 실제 engine.ts도 헤더에 magic bytes, version, flags, 생성/수정 시간, total/active record 수를 기록하는 구조를 갖고 있습니다. 즉, 이건 “파일에 JSON 덤프”가 아니라 작은 스토리지 엔진입니다. (GitHub)
이 설계가 중요한 이유는 세 가지입니다.
- 시작 속도와 파일 크기 관리가 쉬워집니다.
- 레코드별 손상 여부를 검출할 수 있습니다.
- 삭제/업데이트를 위한 내부 상태 관리를 넣기 쉬워집니다.
개발자 입장에서는 “단순한 로컬 저장소”처럼 쓰지만, 내부적으로는 DB다운 최소한의 메타데이터 계층이 있습니다. (GitHub)
예를 들면 사용 방식은 굉장히 단순합니다.
import { AgentDB } from "./src/database.js";
const db = new AgentDB("./my-data", {
compressionEnabled: true,
encryptionKey: "super-secret-password",
});
await db.open();
const users = db.collection("users");
users.insert({ name: "Alice", age: 29, role: "admin" });
users.insert({ name: "Bob", age: 34, role: "user" });
const admins = users.query()
.where("age", ">=", 18)
.where("role", "==", "admin")
.sort("name", "asc")
.exec();
console.log(admins);
db.close();
이 API는 Mongo 스타일 문서 모델과 SQLite식 임베디드 경험을 섞어놓은 느낌입니다. README의 Quick Start도 거의 같은 흐름으로 설명합니다. (GitHub)
핵심 기능 2: 암호화가 “옵션”이 아니라 구조에 들어가 있다
AgentDB에서 가장 눈에 띄는 부분은 보안 기능입니다. README는 AES-256-GCM, PBKDF2-SHA-512 기반 키 유도, 레코드별 랜덤 IV와 auth tag를 명시하고 있고, 실제 encryption.ts도 암호화 출력 형식을 [IV][Auth Tag][Ciphertext]로 구성합니다. 키는 256비트이며, salt를 사용해 파생됩니다. (GitHub)
중요한 건 이게 “파일 전체 암호화”가 아니라 레코드 단위 암호화라는 점입니다. 이런 설계는 전체 파일 재암호화 없이 append/update 흐름에 더 잘 맞고, WAL이나 레코드 검증 구조와도 자연스럽게 결합됩니다. README와 demo 모두 이 부분을 강조합니다. (GitHub)
데모도 꽤 설득력 있게 작성되어 있습니다. demo.ts는 암호화된 DB를 열고 secrets 컬렉션에 값을 넣은 다음, 실제 .agdb 파일 바이트를 읽어 plaintext가 직접 보이지 않는지 확인합니다. 그런 뒤 애플리케이션 레벨에서는 그대로 query해서 복호화된 값을 조회합니다. 즉, “디스크에는 암호문, 코드에서는 투명한 사용성”이라는 UX를 보여줍니다. (GitHub)
이런 코드는 실제 제품 코드에서도 바로 상상할 수 있습니다.
const db = new AgentDB("./secure-data", {
encryptionKey: process.env.AGENTDB_KEY!,
});
await db.open();
const secrets = db.collection("secrets");
secrets.insert({
provider: "openai",
apiKey: "sk-...",
scope: "production",
});
const record = secrets.find({ provider: "openai" })[0];
console.log(record.apiKey); // 앱에서는 평문처럼 사용
에이전트 앱, 로컬 데스크톱 툴, 팀 내부 CLI처럼 민감한 설정값이나 토큰을 로컬에 저장해야 하는 경우 이 포인트가 꽤 큽니다.
핵심 기능 3: WAL로 크래시 복구를 구현했다
이 저장소를 꼭 열어보라고 한 이유가 바로 여기서 드러납니다. AgentDB는 README에서 crash safe를 강조하는데, 그 말이 실제 코드에 반영되어 있습니다. wal.ts에는 WAL 엔트리 포맷이 정의되어 있고, 각 엔트리는 CRC32 + op type + key + timestamp + JSON data 구조로 기록됩니다. 그리고 0xFF commit marker를 두어 배치 커밋 여부를 구분합니다. 손상된 엔트리가 나오면 복구를 멈추는 방어 로직도 들어가 있습니다. (GitHub)
스토리지 엔진 쪽도 WAL을 파일 오픈 시점에 확인하고, pending 상태가 있으면 replay합니다. README 역시 “every write is journalled first”라고 설명합니다. 즉, AgentDB의 crash safety는 단순 슬로건이 아니라 기록 순서에 대한 의도적인 설계입니다. (GitHub)
특히 demo.ts가 이 기능을 눈으로 보여줍니다. 데모는 두 개의 문서를 WAL을 통해 기록한 뒤, close()를 호출하지 않고 일부 핸들만 정리하는 식으로 의도적인 비정상 종료 상황을 만들고, 이후 다시 열어 WAL replay로 두 문서가 복구되는지 확인합니다. 결과 메시지도 “Recovered 2 / 2 records after simulated crash” 형태로 검증합니다. (GitHub)
이건 운영 관점에서 꽤 큰 차이입니다. 로컬 스토리지에서 가장 무서운 건 “조용한 데이터 손실”인데, AgentDB는 최소한 그 리스크를 줄이려는 구조를 갖고 있습니다.
핵심 기능 4: 인덱스가 있어서 그냥 전수 스캔 DB에 머물지 않는다
문서 DB를 로컬 파일로 만들면 흔히 모든 쿼리가 전수 스캔으로 끝납니다. AgentDB는 여기서 한 단계 더 갑니다. README는 field indexes + O(log n) binary search를 내세우고 있고, 실제 indexer.ts는 정렬된 { value, docId } 배열을 유지한 뒤 bisectLeft 같은 binary search helper를 사용합니다. (GitHub)
collection.ts에서도 createIndex(field, unique)를 제공하고, 인덱스 생성 시 기존 문서들로 빌드합니다. insert/update 시에는 인덱스 일관성을 함께 관리하며, unique 제약 위반도 여기서 막습니다. (GitHub)
예를 들면 다음처럼 쓸 수 있습니다.
const orders = db.collection("orders");
orders.createIndex("status");
orders.createIndex("customerId");
orders.createIndex("orderNumber", true); // unique
orders.insert({
orderNumber: "ORD-2026-0001",
customerId: "cus_123",
status: "paid",
total: 129000,
});
const paidOrders = orders.query()
.where("status", "==", "paid")
.exec();
작은 규모에서는 체감이 덜할 수 있지만, 로컬 에이전트 메모리나 작업 로그가 수천~수만 건으로 커지면 이런 차이는 금방 드러납니다.
핵심 기능 5: 단순 CRUD를 넘는 컬렉션 레벨 기능
collection.ts를 보면 AgentDB는 CRUD만 제공하지 않습니다.
TTL부터 보죠. 컬렉션 옵션에 TTL이 있으면 insert 시 _ttl을 자동으로 계산해 넣고, 조회 시 lazy expiry를 적용하며, DB 레벨에서는 60초 간격으로 전체 컬렉션의 만료 문서를 정리합니다. 즉, 세션 캐시나 단기 메모리 저장소에 꽤 잘 맞습니다. (GitHub)
스키마 검증도 있습니다. schema.ts는 필수값, enum, regex, min/max, 타입 검사뿐 아니라 custom validator까지 허용합니다. 로컬 문서 DB에서 자주 빠지는 기능인데, 이 프로젝트는 초기에부터 넣었습니다. (GitHub)
업데이트 흐름도 꽤 실용적입니다. update 외에 upsert와 replace가 있고, insert/update/delete/compact 이벤트도 발생시킵니다. README에 적힌 “event emitters, upsert / replace”가 실제 구현과 맞물립니다. (GitHub)
예를 들면 에이전트 실행 로그 저장소를 이렇게 만들 수 있습니다.
const runs = db.collection("runs", {
ttl: 7 * 24 * 60 * 60 * 1000, // 7일 보관
});
runs.setSchema({
agentId: { type: "string", required: true },
status: { type: "string", enum: ["queued", "running", "done", "failed"], required: true },
latencyMs: { type: "number", min: 0 },
});
runs.insert({
agentId: "planner",
status: "running",
latencyMs: 120,
});
이 정도면 단순 파일 저장을 넘어, 작은 제품 기능을 바로 붙일 수 있는 수준의 로컬 DB API라고 볼 수 있습니다.
핵심 기능 6: 검색, 집계, 커서까지 들어가 있다
이 프로젝트가 재미있는 건 “엔진 만든 김에 문서 API도 꽤 넓게 가져갔다”는 점입니다. Query builder는 .where(), .sort(), .limit(), .skip(), .select(), .first(), .exists(), .count() 흐름을 지원하고, Query 클래스가 이를 직접 관리합니다. README와 collection.ts가 일치합니다. (GitHub)
또 collection.ts에는 간단한 full-text search가 있고, aggregation.ts에는 sum, avg, min, max, count, distinct, percentile 같은 집계 함수가 구현되어 있습니다. 특히 percentile까지 넣은 건 생각보다 공을 많이 들였다는 신호입니다. (GitHub)
이 기능은 예를 들어 운영 로그 분석에 바로 연결됩니다.
const metrics = db.collection("metrics");
metrics.insert({ route: "/chat", latencyMs: 120, status: 200 });
metrics.insert({ route: "/chat", latencyMs: 350, status: 200 });
metrics.insert({ route: "/chat", latencyMs: 900, status: 500 });
const p95 = metrics.aggregate().percentile("latencyMs", 95);
const distinctStatus = metrics.aggregate().distinct("status");
console.log({ p95, distinctStatus });
대형 분석 시스템을 대체할 수준은 아니지만, 로컬 개발도구, 임시 분석 저장소, 단일 노드 앱에는 꽤 실용적인 기능 폭입니다.
프로젝트 아키텍처 분석
AgentDB를 구조적으로 보면 크게 5층으로 이해하면 쉽습니다.
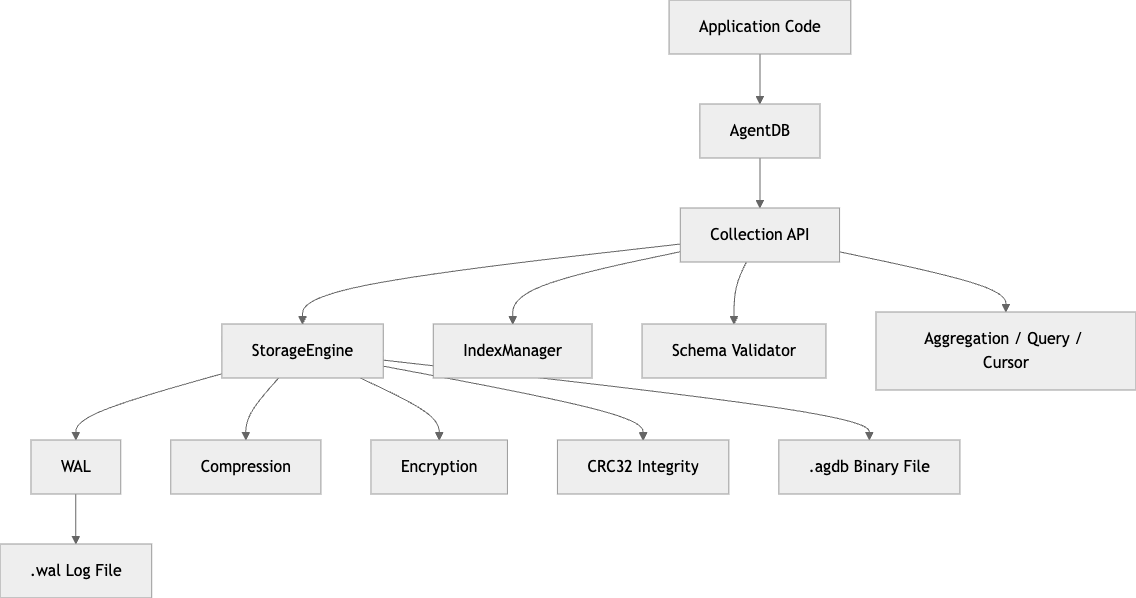
이 구조에서 핵심은 Collection이 개발자 경험의 중심이고, 실제 디스크 I/O 복잡성은 StorageEngine으로 밀어 넣었다는 점입니다. DB 객체는 락 획득, 컬렉션 로딩, 백업/마이그레이션, TTL purge 스케줄링을 담당하고, 각 컬렉션은 문서 맵·오프셋 맵·인덱스·스키마·이벤트를 관리합니다. 그 아래에서 엔진은 헤더, 레코드 append/update/delete, WAL replay, 암호화/압축/체크섬을 책임집니다. (GitHub)
좀 더 흐름 중심으로 보면 이렇습니다.
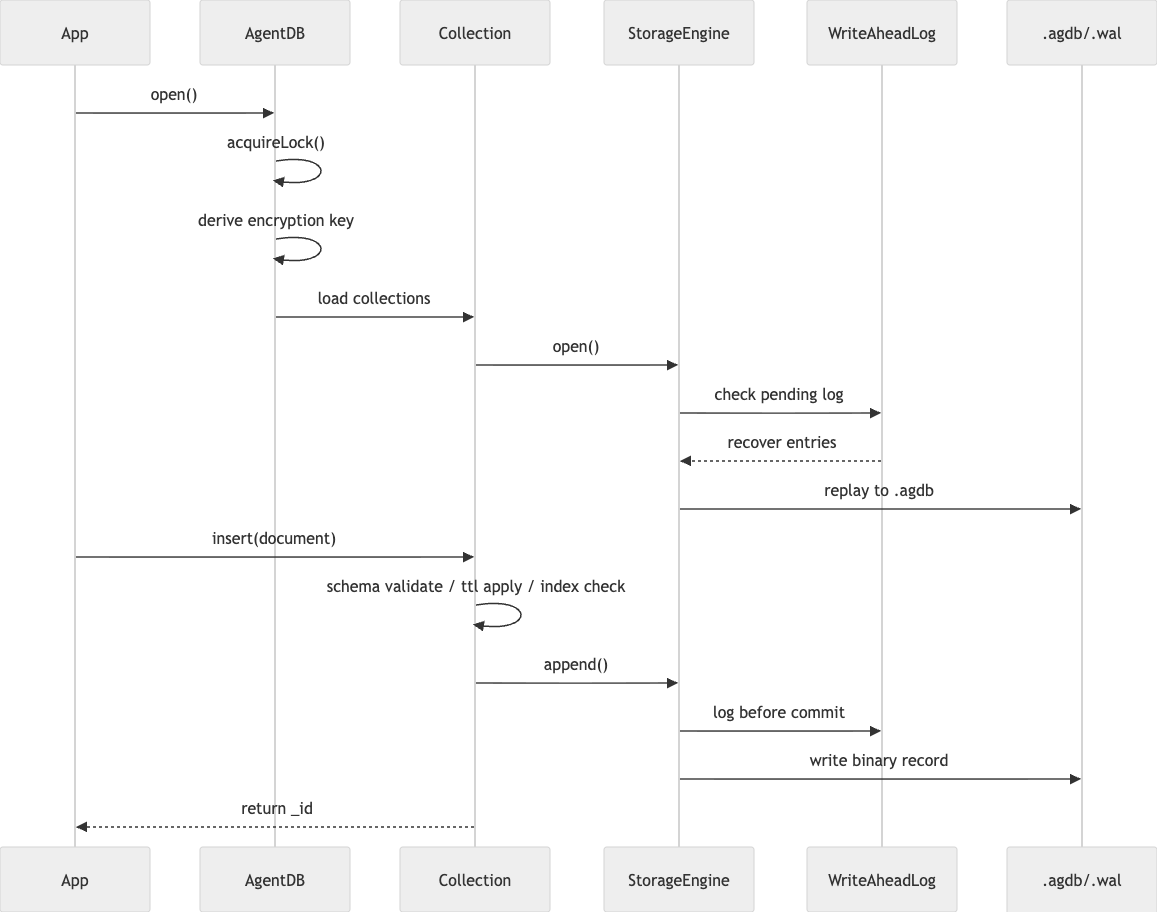
이 설계에서 인상적인 부분은 두 가지입니다.
첫째, 개발자 API는 단순하지만 내부 계층은 꽤 정교하게 분리되어 있습니다. 둘째, zero deps 조건에서도 DB 엔진의 본질적인 문제들—무결성, 복구, 인덱싱, 포맷 관리—를 빠뜨리지 않으려 했다는 점입니다. (GitHub)
이 프로젝트의 강점
제가 이 저장소를 자세히 보고 느낀 가장 큰 강점은 일관성 있는 문제 정의입니다. AgentDB는 “문서 저장소 + 로컬 파일 + 안전성”이라는 하나의 방향을 끝까지 밀고 갑니다. 암호화, WAL, CRC32, lock file, backup, TTL, schema, migration이 전부 같은 방향을 가리킵니다. 단순히 기능 나열형 저장소가 아닙니다. (GitHub)
또 하나는 교육적인 가치입니다. 이 프로젝트는 프로덕션 오픈소스로서 의미도 있지만, 동시에 “Node.js로 직접 스토리지 엔진을 만들면 무엇을 고려해야 하는가”를 보여주는 살아있는 예제이기도 합니다. 헤더 포맷, 로그 구조, 인덱스 설계, TTL purge, 레코드 무결성, 배치 커밋 같은 주제가 코드에 그대로 담겨 있습니다. (GitHub)
아쉬운 점도 분명하다
반대로, 현재 시점에서 바로 대규모 운영용 DB로 보기엔 조심해야 할 부분도 있습니다.
가장 먼저, 아직 초기 단계 저장소입니다. README에 npm publish 예정이라고 되어 있고, 패키지 메타데이터 일부도 정리 중입니다. 저장소 히스토리도 매우 짧습니다. 즉, 지금은 “성숙한 대체재”보다 매우 야심찬 초기 구현으로 보는 게 맞습니다. (GitHub)
또한 README의 비교표는 방향성을 잘 보여주지만, SQLite나 MongoDB와의 실전 비교는 아직 더 많은 벤치마크와 운영 사례가 필요합니다. 저장소 안에는 데모와 테스트가 있지만, 분산 환경, 다중 프로세스 경쟁, 대용량 데이터셋, 장기적 포맷 호환성 같은 현실 검증은 앞으로 더 쌓여야 합니다. 저장소에 process lock은 있지만 설계상 단일 프로세스/단일 인스턴스 사용이 기본 전제에 가깝습니다. (GitHub)
언제 쓰면 좋은가
이 프로젝트는 아래 상황에서 특히 잘 어울립니다.
1. 로컬 AI 에이전트 상태 저장소
대화 히스토리, 툴 실행 로그, 캐시, 임시 계획, 단기 메모리를 문서 단위로 저장하고 싶을 때 좋습니다. TTL, schema, encryption 조합이 특히 잘 맞습니다. (GitHub)
2. CLI / 데스크톱 앱의 내장 DB
Electron 앱, 내부 운영 툴, 로컬 자동화 도구처럼 “서버 띄우기 싫은” 제품에 적합합니다. 별도 서비스 없이 프로젝트 디렉터리 안에서 끝낼 수 있습니다. (GitHub)
3. 민감한 설정값의 로컬 저장
API 키, 사용자 비밀값, 워크플로 토큰을 단순 JSON보다 안전하게 저장하고 싶을 때 유용합니다. AES-256-GCM과 레코드 단위 암호화가 여기서 빛납니다. (GitHub)
4. “DB를 공부하는” 개발자
스토리지 엔진의 최소 기능을 어떻게 조합하는지 배우고 싶은 개발자에게도 좋습니다. WAL, CRC, compaction, index, schema, migration의 관계를 한 저장소에서 보기 쉽습니다. (GitHub)
언제는 아직 조심해야 할까
반대로 이런 경우는 아직 보수적으로 보는 게 맞습니다.
- 다중 노드 서버 환경
- 복잡한 동시성 제어가 필요한 워크로드
- 초대형 데이터셋
- 검증된 운영 이력과 생태계가 반드시 필요한 서비스
- SQL 조인, 복잡한 트랜잭션, 리플리케이션이 중요한 시스템
이럴 땐 SQLite, Postgres, MongoDB 같은 검증된 선택지가 여전히 우위입니다. AgentDB는 그들을 완전히 대체한다기보다, “작고 안전한 로컬 문서 저장소”라는 틈새를 정교하게 파고드는 프로젝트에 더 가깝습니다. README의 비교표도 정확히 그 포지션을 겨냥합니다. (GitHub)
한 줄로 정리하면
AgentDB는 “Node.js 안에서 돌아가는 작은 문서 DB”를 만들되, 파일 저장소 수준이 아니라 진짜 스토리지 엔진처럼 만들자는 프로젝트입니다. 바이너리 포맷, 레코드 체크섬, AES-256-GCM, WAL 복구, 필드 인덱스, TTL, 스키마, 집계까지 직접 구현한 점이 이 저장소의 핵심 가치입니다. (GitHub)
아직 초기 단계지만, 방향은 아주 선명합니다. 특히 AI 도구, 로컬 런타임, CLI, 데스크톱 앱 같은 세계에서는 이런 설계가 꽤 매력적입니다. “SQLite의 임베디드 감각”과 “Mongo 스타일 문서 모델” 사이를, 보안과 복구까지 챙기며 Node.js로 직접 메운 프로젝트라고 보면 가장 정확합니다. (GitHub)
'AI' 카테고리의 다른 글
| Sherlock: 사용자명 하나로 SNS 모든 계정 AI로 추적 (0) | 2026.03.31 |
|---|---|
| Cua: Computer-Use Agents를 위한 오픈소스 (1) | 2026.03.31 |
| 🚪 Claude Code의 숨겨진 15가지 기능 (0) | 2026.03.30 |
| Open Agent Platform: LangGraph 에이전트를 “앱처럼” 만들고 운영하게 만든 실험 (0) | 2026.03.30 |
| OpenBB: 금융 데이터를 하나의 API로 통합하는 오픈소스 데이터 플랫폼 (0) | 2026.03.30 |