
- IT (1650)

오늘도 공부
LangGraph와 Claude Code가 바꾸는 개발 방식 본문
이제는 AI 한 명이 아니라, 협업하는 AI 팀을 설계할 때다
불과 얼마 전까지만 해도 개발자에게 필요한 AI는 “질문에 잘 답하는 챗봇 하나”였습니다. 그런데 2026년의 흐름은 확실히 다릅니다. 지금 커뮤니티가 주목하는 건 더 똑똑한 단일 모델이 아니라, 역할이 다른 여러 에이전트를 어떻게 조합하고 협력시킬 것인가입니다. dev.to에서 화제가 된 CopilotKit + LangGraph 조합은 바로 이 지점을 겨냥합니다. 하나의 거대한 프롬프트로 모든 걸 해결하려는 대신, 요약 에이전트, 질의응답 에이전트, 코드 생성 에이전트를 분리하고 그래프 형태로 연결해 실서비스에 가까운 구조를 만듭니다. LangGraph는 장기 실행·상태 관리·복구 가능한 워크플로를 위한 오케스트레이션 프레임워크이고, CopilotKit은 이런 에이전트를 React/Next.js UI와 연결하는 데 초점을 둡니다. (DEV Community)
이 흐름이 더 흥미로운 이유는, 코딩 에이전트 자체도 빠르게 “실행 가능한 동료” 쪽으로 진화하고 있기 때문입니다. Claude Code는 단순 코드 추천 도구가 아니라 코드베이스를 읽고, 파일을 수정하고, 명령을 실행하고, IDE·터미널·브라우저와 연결되는 에이전트형 코딩 시스템으로 소개됩니다. 즉 이제 프롬프트를 잘 쓰는 것만으로는 부족하고, 어떤 에이전트에 어떤 권한과 역할을 줄지, 어떤 순서와 상태 전이로 협업시킬지가 개발자의 핵심 역량이 되어가고 있습니다. (Claude)
Building a Production-Ready Composable AI Agent System with CopilotKit and LangGraph
Introduction Building AI agents is one thing. Building agents that actually work together...
dev.to
이 프로젝트는 무엇인가
이번에 dev.to에서 다룬 예제는 “조립 가능한 멀티 에이전트 시스템”을 실제 웹 애플리케이션 형태로 구현한 사례입니다. 프론트엔드는 Next.js 14와 TypeScript를 사용하고, UI 계층은 CopilotKit이 맡습니다. 백엔드는 FastAPI로 구성되며, LangGraph가 에이전트 워크플로를 정의합니다. 예제 안에서는 세 개의 역할이 등장합니다.
하나는 입력을 먼저 정리하는 Summarizer,
하나는 내용을 해석하고 질문에 답하는 Q&A,
마지막 하나는 실제 산출물을 만드는 Code Generator입니다.
이들은 순차적으로 연결되지만, 서로 독립적인 노드로 설계되기 때문에 교체·확장·재사용이 쉽습니다. (DEV Community)
이 구조가 중요한 이유는 명확합니다. 기존의 “하나의 거대한 에이전트”는 데모에는 잘 맞아도 운영에는 약합니다. 어디서 실패했는지 추적하기 어렵고, 특정 단계만 교체하기도 힘들고, 테스트 단위가 모호해집니다. 반면 LangGraph 식 접근은 각 단계를 명시적인 노드와 상태 전이로 다루기 때문에, 에러 복구·관찰성·부분 재실행 같은 운영 관점의 요구를 더 자연스럽게 받아들입니다. LangGraph 공식 문서도 워크플로와 에이전트를 구분하면서, persistence, streaming, interrupts, memory, deployment 같은 운영 기능을 핵심 장점으로 내세웁니다. (DEV Community)
왜 지금 이런 구조가 뜨는가
핵심 배경은 두 가지입니다.
첫째, 단일 에이전트 방식의 한계가 너무 빨리 드러났기 때문입니다.
하나의 모델에게 “문서 읽고, 계획 세우고, 코드 짜고, 테스트하고, 결과 요약까지 다 해”라고 맡기면 처음에는 놀랍습니다. 하지만 조금만 복잡한 작업으로 가면 맥락이 엉키고, 중간 상태를 제어하기 어렵고, 실패 원인도 불명확해집니다. LangGraph가 워크플로를 강조하는 이유도 이 때문입니다. 공식 가이드에서는 workflow는 미리 정해진 경로를 갖고, agent는 동적으로 도구와 경로를 선택한다고 설명합니다. 즉 실무에서는 두 개념을 적절히 섞어야 합니다. 무조건 자유로운 에이전트가 정답이 아니라, 예측 가능한 파이프라인과 자율성의 균형이 중요합니다. (LangChain 문서)
둘째, 비용과 배포 방식이 달라지고 있기 때문입니다. 최근 Google은 Gemma 4를 “advanced reasoning”과 “agentic workflows”에 초점을 둔 오픈 모델로 발표했고, 소비자용 GPU에서도 로컬 퍼스트 서버처럼 활용할 수 있다고 설명했습니다. LM Studio는 CLI인 lms를 통해 로컬 모델 서버를 자동화할 수 있게 했습니다. 이 말은 곧, 이제는 모든 에이전트를 비싼 클라우드 API 하나에만 걸 필요가 없다는 뜻입니다. 계획 수립은 클라우드 고성능 모델이 맡고, 반복 요약이나 분류는 로컬 모델이 맡는 하이브리드 오케스트레이션이 현실적인 선택지가 되기 시작했습니다. (Google DeepMind)
그리고 Claude Code 같은 도구는 이 변화의 반대편에서 실무 감각을 밀어 올리고 있습니다. 단지 답변을 생성하는 것이 아니라, 코드베이스를 조작하고 명령을 실행하는 수준까지 내려왔기 때문에, 오케스트레이션 대상이 “텍스트 생성기”가 아니라 “행동하는 작업자”가 됩니다. 이 순간부터 개발자는 프롬프트 엔지니어가 아니라 작업 분배자이자 시스템 설계자가 됩니다. (Claude)
핵심 기능을 개발자 관점에서 보면
1. 역할 분리
요약, 분석, 생성, 검증을 각각 다른 노드로 분리하면 실패 지점을 찾기 쉬워집니다. 특정 단계의 품질이 떨어질 때 전체 프롬프트를 갈아엎는 대신, 해당 노드만 교체하면 됩니다. 이것이 composable의 진짜 의미입니다. (DEV Community)
2. 상태 기반 흐름 제어
LangGraph의 강점은 단순 체이닝이 아니라 상태를 가진 그래프라는 점입니다. 중간 산출물, 승인 여부, 재시도 횟수, 사용자 피드백을 모두 상태로 들고 다음 노드에 넘길 수 있습니다. 장기 실행과 복구가 필요한 이유도 여기서 나옵니다. (LangChain 문서)
3. UI와 에이전트의 실시간 연결
CopilotKit은 단순 채팅창이 아닙니다. React 앱 안에서 에이전트 상태, 진행 상황, 출력, 툴 호출을 UI에 연결하는 프론트엔드 스택에 가깝습니다. 즉 “모델 호출”과 “사용자 경험” 사이의 간극을 줄여줍니다. (docs.copilotkit.ai)
4. 운영 친화성
실무에서는 “잘 된다”보다 “망가졌을 때 보이느냐”가 더 중요합니다. LangGraph는 디버깅, 추적, 배포, 메모리, human-in-the-loop를 핵심 기능으로 제시합니다. 이건 곧 프로덕션 시스템에 필요한 체크리스트와 거의 겹칩니다. (LangChain 문서)
프로젝트 아키텍처 분석
이 예제의 본질은 꽤 단순합니다.
사용자 입력이 들어오면, 프론트엔드 채팅 UI가 요청을 Next.js API로 보내고, 그 요청이 LangGraph 기반 백엔드로 전달됩니다. 백엔드에서 여러 에이전트 노드가 순차 혹은 조건부로 실행되고, 결과는 스트리밍으로 다시 UI에 반영됩니다. dev.to 글의 흐름은 Next.js → CopilotKit runtime → FastAPI → LangGraph agent workflow → LLM 호출 → 실시간 스트리밍 응답이라는 형태입니다. (DEV Community)

이 구조를 더 실무적으로 바꾸면 보통 아래처럼 됩니다.
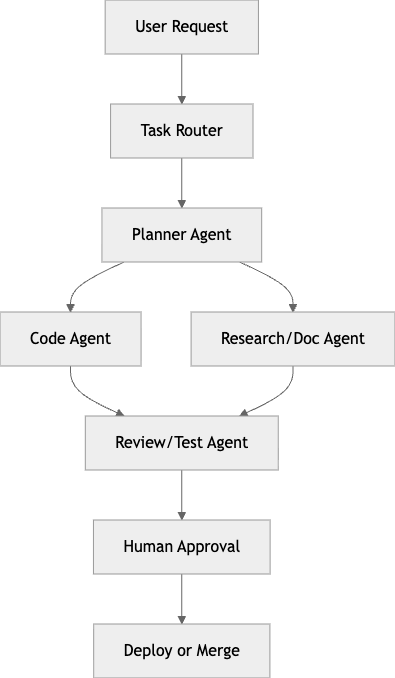
여기서 중요한 점은, 모든 단계를 에이전트로 만들 필요는 없다는 것입니다.
실제로는 아래처럼 나누는 편이 더 안정적입니다.
- 라우팅과 승인 조건은 코드로 고정
- 생성과 해석만 LLM에게 위임
- 테스트와 배포는 기존 CI/CD에 연결
즉, 오케스트레이션은 “AI가 다 알아서 하게 만드는 기술”이 아니라, AI가 잘하는 구간만 그래프 안에 안전하게 배치하는 기술에 가깝습니다.
코드로 보면 왜 이해가 쉬운가
dev.to 글에서도 핵심은 결국 이 한 줄입니다. “거대한 함수 하나” 대신 “노드 여러 개를 그래프로 엮는다.” (DEV Community)
안 좋은 예: 모든 걸 한 함수에 몰아넣기
def handle_request(user_input: str):
summary = summarize(user_input)
answer = answer_questions(summary)
code = generate_code(answer)
tests = run_tests(code)
return {
"summary": summary,
"answer": answer,
"code": code,
"tests": tests,
}
처음엔 단순해 보이지만, 문제가 생기면 어디가 원인인지 추적하기 어렵습니다.
더 나은 예: LangGraph 스타일의 노드 분리
from typing import TypedDict
from langgraph.graph import StateGraph, START, END
class AgentState(TypedDict):
user_input: str
summary: str
answer: str
code: str
test_result: str
def summarizer_node(state: AgentState):
summary = f"[summary] {state['user_input']}"
return {"summary": summary}
def qna_node(state: AgentState):
answer = f"[answer based on] {state['summary']}"
return {"answer": answer}
def codegen_node(state: AgentState):
code = f"# code generated from: {state['answer']}"
return {"code": code}
def test_node(state: AgentState):
# 실제로는 pytest, lint, type check 등을 호출
return {"test_result": "passed"}
graph = StateGraph(AgentState)
graph.add_node("summarizer", summarizer_node)
graph.add_node("qna", qna_node)
graph.add_node("codegen", codegen_node)
graph.add_node("test", test_node)
graph.add_edge(START, "summarizer")
graph.add_edge("summarizer", "qna")
graph.add_edge("qna", "codegen")
graph.add_edge("codegen", "test")
graph.add_edge("test", END)
app = graph.compile()
result = app.invoke({"user_input": "사용자 인증 모듈 테스트 코드 만들어줘"})
print(result)
이렇게 바꾸면 얻는 이점은 분명합니다.
- 각 단계별 테스트가 가능하다
- 실패 노드만 다시 실행하기 쉽다
- 새로운 Review Agent를 뒤에 붙이기 쉽다
- 로컬 모델과 클라우드 모델을 단계별로 섞기 쉽다
Claude Code를 어디에 붙이면 좋을까
많은 개발자가 여기서 착각합니다. Claude Code는 오케스트레이터가 아니라, 아주 강력한 실행형 코딩 작업자에 가깝습니다. 공식 문서 기준으로 Claude Code는 코드베이스를 읽고, 파일을 수정하고, 명령을 실행하고, 여러 개발 도구와 통합됩니다. (Claude)
그래서 실무적으로는 보통 이렇게 배치하는 편이 좋습니다.
추천 역할 분담
- LangGraph: 흐름 제어, 상태 관리, 승인 절차, 분기 처리
- Claude Code: 실제 코드 수정, 테스트 실행, 리팩터링, 버그 수정
- CopilotKit: 사용자가 중간 진행 상황을 보고 개입할 수 있는 UI
- 로컬 모델(Gemma 4 + LM Studio 등): 저비용 반복 작업, 요약, 분류, 초안 생성
이렇게 두면 “가벼운 일은 로컬”, “정확도가 중요한 코드 작업은 강한 모델”, “전체 흐름은 그래프”라는 구조가 됩니다. Gemma 4가 agentic workflows를 강조하며 공개됐고, LM Studio CLI가 로컬 모델 자동화를 지원한다는 점을 생각하면, 이 조합은 앞으로 더 흔해질 가능성이 큽니다. (Google DeepMind)
1인 개발자에게 가장 현실적인 구성
여기서 가장 중요한 질문은 이것입니다.
“처음부터 AI 어벤져스 팀을 다 만들 필요가 있을까?”
제 답은 아니오입니다.
1인 개발자라면 아래 3단계 구성이 가장 현실적입니다.
단계 1: Planner + Coder + Reviewer
가장 먼저 만들 만한 최소 조합입니다.

- Planner: 요구사항을 작업 단위로 분해
- Code Agent: 실제 구현
- Review/Test Agent: 테스트, 린트, 정적 검사, 위험 변경 탐지
이 구성만으로도 “혼자 개발하지만 최소한 코드 리뷰 체계는 있는 팀” 같은 느낌이 납니다.
단계 2: Human Approval 추가
에이전트가 바로 main 브랜치에 머지하게 두지 말고, 승인 단계를 넣어야 합니다.
def approval_node(state):
if state.get("risk_level") == "high":
return {"next_step": "human_review"}
return {"next_step": "deploy"}
이 한 단계가 실무 품질을 크게 바꿉니다.
단계 3: 로컬 모델 분리
비용 절감이 필요하면 반복 작업을 로컬 모델에 넘깁니다.
- 문서 요약
- 로그 분류
- 변경 내역 설명
- 커밋 메시지 초안
- 테스트 결과 요약
반면 아래는 여전히 상위 모델이나 신뢰 높은 코딩 에이전트에 남겨두는 편이 좋습니다.
- 큰 리팩터링
- 복잡한 버그 수정
- 아키텍처 변경
- 보안 민감 코드 수정
실무 적용 가이드
이 조합을 실제 제품에 넣으려면, 멋진 데모보다 아래 네 가지가 더 중요합니다.
1. 상태 스키마를 먼저 정의하라
에이전트를 만들기 전에 state가 무엇을 들고 다닐지 정의해야 합니다.
class WorkflowState(TypedDict):
task: str
plan: list[str]
code_diff: str
test_report: str
review_comment: str
approval_required: bool
프롬프트보다 상태 설계가 먼저입니다.
2. 각 에이전트의 책임을 한 문장으로 제한하라
“이 에이전트는 무엇까지 하고 무엇은 하지 않는가”가 명확해야 합니다.
역할이 겹치면 충돌하고, 프롬프트가 길어지고, 디버깅이 어려워집니다.
3. 모든 자율 단계 앞뒤에 검증을 넣어라
- 코드 생성 뒤에는 테스트
- 배포 전에는 승인
- 외부 도구 호출 전에는 권한 체크
Claude Code처럼 실제 파일과 명령을 건드리는 도구는 특히 이 안전장치가 중요합니다. (Claude)
4. 관찰성을 반드시 확보하라
LangGraph가 persistence, debugging, deployment를 강조하는 이유가 여기 있습니다. 운영 환경에서는 “왜 이런 답이 나왔는지”보다 “어느 노드에서 어떤 상태로 실패했는지”가 더 중요합니다. (LangChain 문서)
이 조합이 특히 잘 맞는 사례
이런 시스템은 아래 같은 작업에 잘 맞습니다.
기능 개발 자동화
- PRD 요약
- 작업 계획 생성
- 코드 생성
- 테스트 작성
- PR 설명 자동 작성
고객 지원/사내 도구
- 사용자 질문 분류
- 관련 문서 검색
- 답변 초안 생성
- 정책 검토
- 상담원 승인
운영 자동화
- 로그 요약
- 장애 원인 후보 정리
- 대응 스크립트 제안
- 포스트모템 초안 작성
반대로 아직은 덜 맞는 영역도 있습니다.
- 완전 자율 배포
- 고위험 보안 변경
- 재무·법률처럼 작은 실수도 큰 비용이 되는 영역
- 명확한 검증 기준이 없는 창의 작업 전부
즉, 조립형 에이전트는 만능이 아니라 검증 가능한 단계가 있는 업무에서 가장 빛납니다.
결국 중요한 건 “에이전트 수”가 아니라 “지휘 체계”다
지금 커뮤니티가 흥분하는 이유는 이해가 됩니다. 정말로 잘 설계하면, 혼자 개발하는 사람도 기획자·개발자·리뷰어가 분리된 작은 팀처럼 일할 수 있기 때문입니다. 하지만 핵심은 AI를 많이 붙이는 것이 아닙니다. 핵심은 다음 세 가지입니다.
- 어떤 역할로 분리할 것인가
- 어떤 상태를 공유할 것인가
- 어디서 사람의 승인을 받을 것인가
LangGraph는 이 흐름을 설계하기 위한 뼈대를 제공하고, CopilotKit은 그 흐름을 사용자 경험으로 연결하며, Claude Code는 그 안에서 실제 작업을 수행하는 강력한 실행자로 배치될 수 있습니다. 여기에 Gemma 4 같은 로컬 모델과 LM Studio 같은 도구가 더해지면, 앞으로의 에이전트 시스템은 “클라우드에 전부 의존하는 비싼 데모”가 아니라 로컬과 클라우드를 섞어 쓰는 운영 가능한 팀 구조로 갈 가능성이 큽니다. (GitHub)
한 줄로 정리하면 이렇습니다.
이제 AI 활용의 승부처는 프롬프트가 아니라 오케스트레이션이다.
그리고 그 오케스트레이션은, 생각보다 훨씬 빨리 실무의 기본기가 되고 있습니다.
'AI' 카테고리의 다른 글
| Mini-Coding-Agent: 코딩 에이전트의 핵심만 남긴, 가장 읽기 쉬운 로컬 에이전트 구현 (0) | 2026.04.07 |
|---|---|
| Field Theory CLI: 북마크를 데이터 자산으로 바꾸는 CLI (0) | 2026.04.07 |
| RTK: AI 코딩 에이전트의 토큰 낭비를 줄이는 가장 현실적인 방법 (0) | 2026.04.07 |
| 9B 로컬 모델을 멀티스텝 에이전트로 바꾼 10가지 아키텍처 최적화 (0) | 2026.04.07 |
| Trellis: 여러 AI 코딩 도구를 하나의 개발 워크플로로 묶는 오픈소스 프레임워크 (0) | 2026.04.07 |