
- IT (1650)

오늘도 공부
9B 로컬 모델을 멀티스텝 에이전트로 바꾼 10가지 아키텍처 최적화 본문
GPT-4급 API 없이도 된다
9B 로컬 모델을 멀티스텝 에이전트로 바꾼 10가지 아키텍처 최적화
작은 모델은 원래 “말은 그럴듯하게 하지만 끝까지 일을 완수하진 못하는” 경우가 많습니다.
특히 로컬 환경에서 돌리는 7B~9B급 모델은 채팅은 가능해도, 파일을 읽고, 툴을 부르고, 중간 결과를 정리하고, 다시 다음 행동을 선택하는 에이전트형 작업으로 들어가면 금방 흔들립니다.
그런데 최근 한 실험이 꽤 흥미로운 메시지를 던졌습니다.
더 큰 모델로 갈아타지 않고도, 그리고 비싼 API를 붙이지 않고도, 아키텍처를 잘 설계하면 9B 로컬 모델도 실제 작업을 끝내는 에이전트처럼 동작할 수 있다는 겁니다. 작성자는 qwen3.5:9b를 NVIDIA RTX 5070 Ti에서 돌리며, 프롬프트 구조화·툴 출력 압축·메모리 분리·단계 전환 제어 같은 10가지 최적화를 적용해 “비용 0”에 가까운 로컬 에이전트 실행을 구현했다고 설명합니다. (DEV Community)
이 글은 원문을 그대로 옮기지 않고,
왜 이런 최적화가 작은 모델에 특히 잘 먹히는지,
각 기법이 에이전트 시스템에서 어떤 역할을 하는지,
실제로 구현한다면 어떤 식으로 설계하면 되는지를 개발자 관점에서 다시 풀어쓴 글입니다. (DEV Community)
10 Architectural Optimizations That Turned My 9B Model into a Zero-Cost, Task-Completing Local AI Agent
10 Architectural Optimizations That Turned My 9B Model into a Zero-Cost, Task-Completing Local AI...
dev.to
이 프로젝트가 말하는 핵심
원문의 메시지는 단순합니다.
작은 모델이 못하는 건 “지능”만의 문제가 아니라,
상당 부분은 시스템 설계 문제다.
작성자가 제시한 수치를 보면 그 의도가 분명합니다.
- 자유형 문장 프롬프트를 표 기반 구조화 프롬프트로 바꾸자 출력 품질이 4점에서 25점 이상으로 올라가며, 체감상 525% 개선되었다고 주장합니다. 속도도 36% 빨라졌다고 합니다. (DEV Community)
- 툴 결과를 그대로 넣지 않고 MicroCompact 방식으로 압축하면 컨텍스트 점유를 80~93% 줄일 수 있다고 설명합니다. (DEV Community)
- 6단계 이후에는 더 이상 툴을 계속 쓰게 두지 않고, 강제로 텍스트 출력 모드로 전환하자 멀티스텝 성공률이 거의 0%에 가까운 수준에서 안정적으로 끝까지 수행되는 수준으로 바뀌었다고 합니다. (DEV Community)
- think=false 설정은 추론 출력 토큰을 1024개에서 131개 수준으로 낮춰 8~10배 절감했다고 합니다. (DEV Community)
- 툴을 처음부터 전부 로드하지 않고 ToolSearch만 먼저 두고 지연 로딩하자 프롬프트 토큰을 339개 절약, 즉 약 60% 감소시켰다고 설명합니다. (DEV Community)
즉, 이 글은 “작은 모델도 똑똑하다”는 낙관론이 아니라,
작은 모델이 실패하는 지점을 시스템적으로 우회하는 법에 가깝습니다. (DEV Community)
왜 이런 접근이 등장했을까
에이전트 시스템을 만들다 보면 금방 부딪히는 문제가 있습니다.
첫째, 작은 모델은 컨텍스트 관리가 서툽니다.
툴 결과를 길게 넣으면 중요한 지시가 묻히고, 이전 단계에서 뭘 했는지 잊어버립니다. 결국 다음 행동을 잘못 고르거나, 같은 툴을 반복 호출합니다. 원문에서 툴 출력 압축과 외부 메모리를 강조하는 이유가 여기 있습니다. (DEV Community)
둘째, 작은 모델은 “탐색 모드”에서 오래 머물수록 무너집니다.
에이전트는 보통 “관찰 → 도구 사용 → 결과 해석 → 다음 행동 선택”을 반복하는데, 이 루프가 길어질수록 모델이 목표보다 과정에 매몰됩니다. 그래서 작성자는 6단계 이후 툴 사용을 끊고 “이제 결과를 작성하라”는 식으로 생산 모드로 강제 전환합니다. 이건 프롬프트 엔지니어링이라기보다 상태 머신 설계에 가깝습니다. (DEV Community)
셋째, 로컬 환경에서는 토큰이 곧 비용이자 지연 시간입니다.
클라우드 API는 돈이 들고, 로컬은 돈 대신 속도·VRAM·맥락 길이 제약이 생깁니다. think=false, 지연 로딩, 안정적인 시스템 프롬프트 유지 같은 기법은 결국 “모델이 진짜 중요한 토큰에만 예산을 쓰게 하는 방법”입니다. (DEV Community)
이 시스템을 한 문장으로 요약하면
**“작은 로컬 모델을 무한히 똑똑하게 만들려는 시도”가 아니라,
“작은 모델이 실수하기 쉬운 부분을 주변 시스템이 대신 통제하는 구조”**입니다. (DEV Community)
이 관점이 중요합니다.
좋은 에이전트는 모델 하나로 완성되지 않습니다.
- 모델은 판단을 한다.
- 시스템은 순서를 제한한다.
- 툴 계층은 정보를 정리한다.
- 메모리는 중요한 것만 남긴다.
- 실행 계층은 실제 결과를 검증한다.
이 조합이 맞아야 “대화형 모델”이 “작업형 에이전트”가 됩니다.
10가지 최적화, 개발자 관점에서 다시 해석하기
1) 자유형 프롬프트 대신 구조화 프롬프트를 사용한다
원문에서 가장 눈에 띄는 건 표 형식 프롬프트입니다.
예를 들어 “이 코드를 분석해줘”라고 던지는 대신, 아래처럼 출력 슬롯을 먼저 정의합니다.
| Category | Location | Fix | Priority |
|----------|----------|-----|----------|
이 방식의 장점은 단순히 예뻐서가 아닙니다.
작은 모델은 자유형 생성에서 쉽게 산만해집니다.
반면 출력 스키마가 명확하면, 모델은 “무엇을 써야 하는가”보다 “칸을 어떻게 채울까”에 집중합니다.
즉, 생성 문제가 구조 채우기 문제로 바뀝니다.
간단히 말해:
- prose prompt: 생각이 많아지고 말이 길어진다
- structured prompt: 항목별로 답하게 되어 흔들림이 줄어든다
원문은 이 방식으로 출력 품질이 525% 올라갔다고 주장합니다. 수치 자체는 작성자의 자체 평가 기준이지만, 작은 모델에선 출력 형식 제약이 성능 향상으로 직결된다는 방향성은 매우 설득력 있습니다. (DEV Community)
예를 들어 코드 리뷰 에이전트라면 이렇게 설계할 수 있습니다.
REVIEW_TEMPLATE = """
당신은 코드 리뷰어다.
반드시 아래 표 형식으로만 응답하라.
| Category | File/Line | Problem | Fix | Priority |
|----------|-----------|---------|-----|----------|
제약:
1. 빈 칸 없이 작성
2. 최대 5개 이슈만 선택
3. 실제 수정 가능한 내용만 적을 것
"""
이건 프롬프트 최적화라기보다,
작은 모델에게 자유도를 너무 많이 주지 않는 UI 설계에 가깝습니다.
2) 툴 결과는 원문 그대로 넣지 말고 압축한다
에이전트가 망가지는 가장 흔한 이유 중 하나는 이겁니다.
- grep
- ls -R
- 로그 출력
- 긴 JSON 응답
- HTML 파싱 결과
이걸 전부 컨텍스트에 다시 밀어 넣으면, 모델은 금방 길을 잃습니다.
원문은 이를 위해 MicroCompact라는 아이디어를 씁니다.
앞부분 몇 줄, 뒷부분 몇 줄, 그리고 중간이 얼마나 생략됐는지를 남기는 방식입니다. 이로 인해 툴 출력 크기를 80~93% 줄였다고 설명합니다. (DEV Community)
핵심은 “모든 정보”가 아니라 다음 판단에 필요한 정보만 유지하는 것입니다.
예시로는 이런 식입니다.
def microcompact(output: str, head: int = 8, tail: int = 5) -> str:
lines = output.splitlines()
if len(lines) <= head + tail:
return output
first = "\n".join(lines[:head])
last = "\n".join(lines[-tail:])
omitted_chars = max(0, len(output) - len(first) - len(last))
return f"{first}\n... ({omitted_chars} chars omitted)\n{last}"
실전에서는 여기에 한 단계 더 가야 합니다.
- stderr는 따로 보존
- exit code는 항상 포함
- 파일 경로/키 이름/에러 타입은 절대 삭제하지 않기
- JSON은 key whitelist 기반으로 요약
즉, 문자 수 압축보다 더 중요한 건 의사결정 신호 보존입니다.
3) 탐색 단계와 생산 단계를 분리한다
이 글에서 가장 실전적인 포인트는 바로 이 부분입니다.
작은 모델은 멀티스텝 루프에 오래 머물수록
“계속 조사만 하고 결론을 못 내리는 상태”에 빠집니다.
원문은 step이 6 이상이 되면 툴 목록을 비워서,
사실상 더 이상 외부 행동을 못 하게 만들고 텍스트 출력 모드로 강제 전환합니다. 이 전략으로 멀티스텝 성공률이 거의 0% 수준에서 안정적인 실행 수준으로 개선됐다고 설명합니다. (DEV Community)
이건 정말 중요합니다.
에이전트 설계에서 많은 개발자가 “모델에게 자유롭게 선택하게 하자”로 가는데, 작은 모델일수록 반대로 가야 합니다.
즉:
- 초반 1~N단계: 탐색
- 이후: 결정
- 마지막: 산출물 생성
이런 식의 유한 상태 머신이 필요합니다.
def allowed_tools(step: int) -> list[str]:
if step < 3:
return ["Search", "ReadFile", "ListDir"]
if step < 6:
return ["ReadFile", "WriteDraft"]
return [] # 이제 결과만 작성
이 구조의 본질은
“모델이 언제 생각을 멈춰야 하는지 시스템이 대신 판단한다”는 점입니다.
4) think=false는 성능 최적화가 아니라 예산 관리다
원문은 think=false 설정으로 토큰 사용량이 1024에서 131로 줄어 8~10배 감소했다고 설명합니다. (DEV Community)
이 숫자가 의미하는 바는 명확합니다.
작은 로컬 모델에선 “긴 사고 과정”이 꼭 도움이 되지 않습니다.
오히려 다음과 같은 문제가 생깁니다.
- 추론 토큰이 너무 길어진다
- 중요한 지시보다 중간 독백이 많아진다
- 멀티스텝 태스크에서 메모리 예산을 잡아먹는다
- 처리 시간이 늘어난다
그래서 실전에서는 이렇게 나누는 게 좋습니다.
- planning pass: 짧고 구조화된 계획만 생성
- execution pass: 툴 호출 및 관찰
- final pass: 결과만 서술
즉, 긴 chain-of-thought를 그대로 노출시키기보다
필요한 의사결정만 표면화하는 구조가 로컬 에이전트에 더 맞습니다.
예시:
MODEL_PARAMS = {
"temperature": 0.2,
"think": False,
}
이 설정은 “생각하지 마라”가 아니라,
쓸데없이 길게 생각을 출력하지 마라에 가깝습니다.
5) 툴셋을 처음부터 다 싣지 말고 지연 로딩한다
에이전트 프롬프트를 길게 만드는 가장 큰 원인 중 하나는
툴 스키마를 한꺼번에 다 붙이는 것입니다.
예를 들어 처음부터 이런 걸 다 넣는 경우가 많습니다.
- 파일 검색
- 웹 검색
- 셸 실행
- 코드 패치
- JSON 파서
- DB 조회
- 브라우저 자동화
하지만 대부분의 작업은 초반에 이 모든 툴이 필요하지 않습니다.
원문은 초기에는 ToolSearch 정도만 노출하고,
필요할 때 나머지를 지연 로딩하는 방식으로 프롬프트 토큰을 339개 줄였고, 약 60% 절감 효과를 봤다고 설명합니다. (DEV Community)
이 방식은 에이전트 설계에서 아주 강력합니다.
INITIAL_TOOLS = ["ToolSearch"]
def resolve_tools(task_state):
if task_state.needs_filesystem:
return INITIAL_TOOLS + ["ReadFile", "ListDir"]
if task_state.needs_write:
return INITIAL_TOOLS + ["ReadFile", "WriteFile", "VerifyWrite"]
return INITIAL_TOOLS
작은 모델 입장에선
“선택지가 적을수록 실수도 적어집니다.”
이건 UX에서도 비슷합니다.
버튼이 30개인 화면보다, 지금 필요한 3개만 보여주는 화면이 사용하기 쉽습니다.
모델도 똑같습니다.
6) 메모리를 컨텍스트 밖으로 분리한다
원문은 외부 메모리와 autoDream 같은 메커니즘을 통해 사용자 선호나 상호작용을 기억하게 했다고 설명합니다. (DEV Community)
이 대목은 “장기 기억”이라는 거창한 표현보다,
컨텍스트 창 바깥에 중요한 상태를 구조화 저장한다고 이해하는 게 맞습니다.
예를 들면 이런 것들입니다.
- 사용자가 선호하는 출력 형식
- 이전 단계에서 확인된 사실
- 이미 성공한 파일 경로
- 실패한 툴 호출 패턴
- 작성 중인 문서의 현재 목적
작은 모델은 긴 대화를 매번 다 기억하지 못합니다.
그러니 기억을 모델 내부에 맡기지 말고, 시스템 메모리로 빼야 합니다.
memory = {
"user_preferences": {
"language": "ko",
"format": "blog",
},
"task_facts": {
"repo_root": "/workspace/app",
"target_file": "src/agent.py",
},
"execution_history": [
{"tool": "ReadFile", "status": "ok"},
]
}
여기서 중요한 건 저장보다 재주입 규칙입니다.
모든 메모리를 다시 넣지 말고,
현재 단계에 필요한 것만 압축해서 넣어야 합니다.
7) KV 캐시 포킹은 이론상 좋지만, 인프라가 받쳐줘야 한다
원문은 KV cache forking을 시도했지만, 작성자의 단일 카드 Ollama 환경에서는 1.1배 정도의 제한적인 가속만 있었다고 설명합니다. 연속 배칭이나 더 적합한 백엔드가 필요하다고 덧붙입니다. (DEV Community)
이건 꽤 솔직한 포인트입니다.
많은 최적화 글이 “엄청난 성능 향상”만 말하는데,
이 항목은 오히려 인프라 의존성을 보여줍니다.
KV 캐시 포킹이 잘 먹히는 경우:
- 동일한 시스템 프롬프트를 공유하는 다중 브랜치
- 같은 prefix에서 여러 후보를 평가하는 구조
- 고성능 inference backend 사용
- continuous batching 지원
반대로 로컬 단일 GPU + 단순 실행 환경에서는
구현 복잡도 대비 이득이 거의 없을 수 있습니다.
즉, 이 최적화는 모든 개발자에게 1순위가 아닙니다.
작은 모델 에이전트를 처음 만든다면, 캐시 포킹보다 프롬프트 구조화와 상태 전환이 훨씬 중요합니다. (DEV Community)
8) 쓰기는 “성공했다고 믿지 말고” 검증해야 한다
원문은 파일 쓰기 후 다시 읽어서 내용이 일치하는지 확인하는 verified write discipline을 제안합니다. 이는 권한 문제나 하드웨어 이슈 같은 실제 실패를 잡기 위한 장치입니다. (DEV Community)
에이전트 시스템에서 이건 매우 중요합니다.
모델은 “썼다”고 말할 수 있지만, 실제 파일은 안 써졌을 수도 있습니다.
그래서 쓰기 단계는 반드시 이렇게 가야 합니다.
- write
- read-back
- diff 확인
- 성공/실패를 메모리에 기록
def verified_write(fs, path, content):
fs.write(path, content)
written = fs.read(path)
ok = written == content
return {
"ok": ok,
"path": path,
"written_bytes": len(written),
}
이 규율이 중요한 이유는
에이전트의 신뢰성을 문장이 아니라 검증된 상태 변화로 확보하기 때문입니다.
작은 모델일수록 자신감 있게 틀리는 경우가 많아서,
실행 계층의 검증이 더 중요합니다.
9) 부팅도 병렬화할 수 있다
원문은 메모리 로드, 모델 예열, 툴 초기화 등을 포함한 7단계 병렬 부팅 파이프라인으로 시작 시간을 1189ms에서 1077ms로 줄여 약 9% 개선했다고 설명합니다. (DEV Community)
이 항목은 앞선 것들보다 임팩트가 작아 보일 수 있습니다.
하지만 로컬 에이전트는 “자주 짧게 실행되는 워크플로”가 많기 때문에, cold start 최적화도 체감이 큽니다.
예를 들어:
- CLI 에이전트
- IDE 보조 도구
- 파일 단위 리팩터링
- 짧은 문서 생성 파이프라인
이런 경우엔 한 번의 100ms 절감도 꽤 크게 느껴집니다.
async def bootstrap():
await asyncio.gather(
load_memory(),
preheat_model(),
initialize_tool_index(),
warmup_parser(),
)
다만 이건 어디까지나 후순위 최적화입니다.
부팅을 10% 빠르게 해도, 중간 단계에서 컨텍스트가 무너지면 전체 성공률은 여전히 낮습니다.
10) 시스템 프롬프트를 안정적으로 유지해 캐시 효율을 높인다
원문은 시스템 프롬프트를 최대한 고정해 동일 요청 처리 시간을 182ms에서 73~77ms 수준으로 줄일 수 있다고 설명합니다. (DEV Community)
이건 로컬 추론 시스템에서 꽤 실용적인 팁입니다.
많은 개발자가 매 요청마다 시스템 프롬프트를 조금씩 바꿉니다.
- 시간 추가
- 작업 설명 추가
- 툴 설명 섞기
- 사용자 상태 직접 삽입
그런데 이렇게 하면 prefix 재사용 이점이 줄어듭니다.
그래서 좋은 구조는 보통 이렇습니다.
- system prompt: 최대한 고정
- task state: 별도 message
- tool schema: 필요 시만 동적 주입
- memory summary: 별도 compact message
즉, 바뀌는 것과 안 바뀌는 것을 분리해야 합니다.
전체 구조는 어떻게 돌아가는가
이 글의 본질을 아키텍처로 그리면 아래와 같습니다.
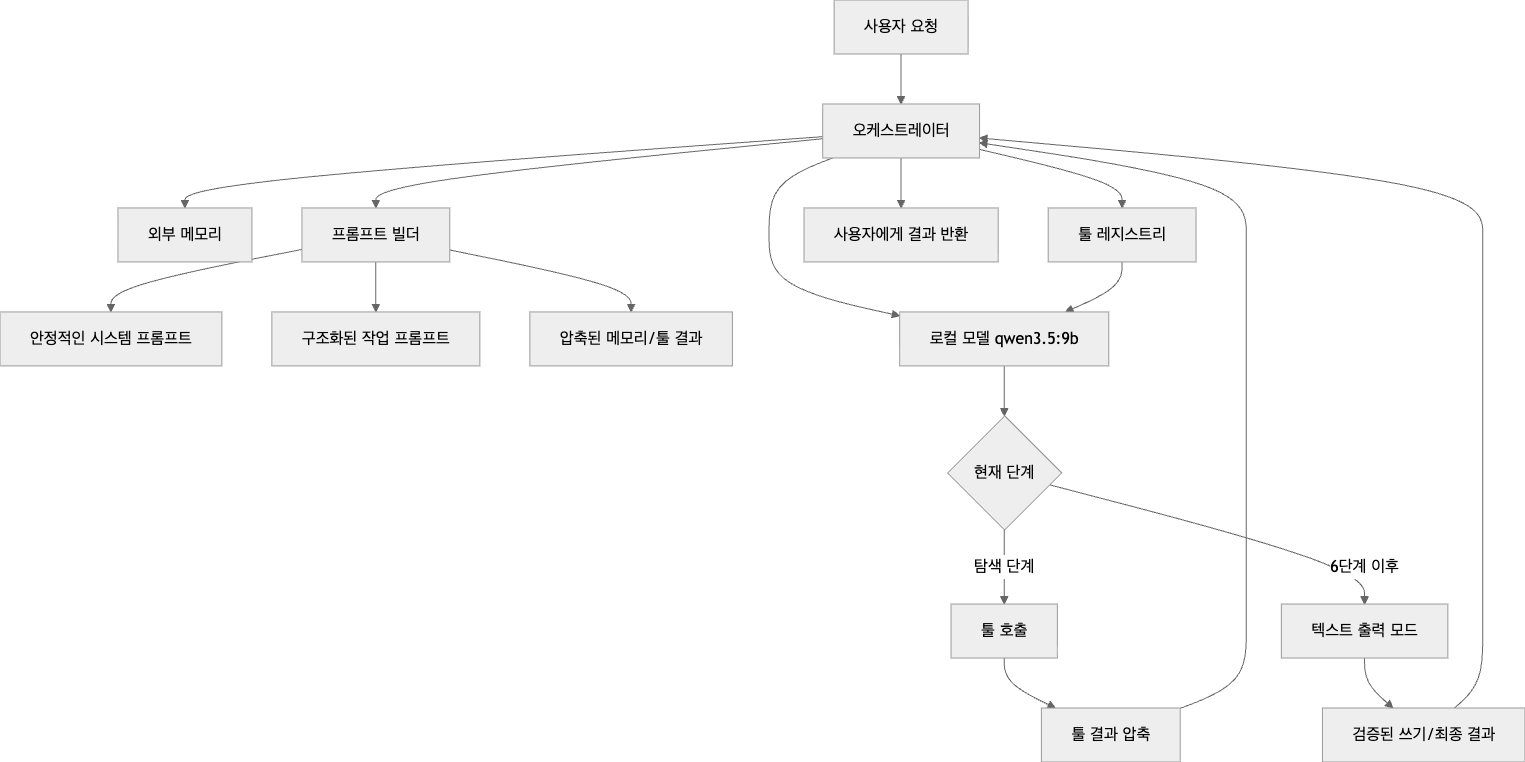
핵심은 세 가지입니다.
- 모델은 모든 걸 결정하지 않는다.
- 오케스트레이터가 단계와 도구를 제한한다.
- 컨텍스트는 원문이 아니라 요약본과 구조화 상태로 유지된다.
이 구조가 바로 작은 모델을 “그럴듯한 채팅봇”에서
“끝까지 일하는 에이전트”로 바꾸는 핵심입니다.
원문에서 제시한 통합 결과는 무엇이었나
원문은 이 10가지 최적화를 local-agent-engine.py라는 약 280줄 수준의 통합 예제로 묶었다고 설명합니다. 그리고 예시 실행 결과로 39.4초, 1473 토큰, 0원 API 비용에 가까운 멀티스텝 작업 처리를 언급합니다. 무료 리소스로 해당 템플릿을 제공한다고도 적었습니다. 다만 이 수치는 작성자의 실험 환경과 워크플로에 기반한 결과로 제시된 것입니다. (DEV Community)
여기서 중요한 건 숫자 자체보다,
그 숫자가 나온 이유입니다.
- 컨텍스트를 아꼈고
- 탐색을 오래 끌지 않았고
- 툴을 필요한 순간에만 열었고
- 출력 형식을 강하게 제약했고
- 실행 결과를 다시 검증했다
즉, 성능 향상의 중심은 모델 변경이 아니라 런타임 설계였습니다. (DEV Community)
이 접근이 특히 잘 맞는 사용처
이 아키텍처는 모든 AI 제품에 맞는 건 아닙니다.
하지만 아래 같은 경우엔 매우 현실적입니다.
1) 로컬 코드 작업 에이전트
- 파일 검색
- 간단한 수정
- 로그 분석
- 테스트 실패 원인 요약
이런 작업은 거대한 창의성이 필요하지 않습니다.
대신 정해진 절차를 안정적으로 수행하는 능력이 더 중요합니다.
2) 문서 생성 자동화
- 릴리스 노트
- 코드 리뷰 요약
- 변경점 정리
- 기술 블로그 초안 생성
이런 경우 구조화 프롬프트와 단계 전환이 특히 잘 맞습니다.
3) 사내 폐쇄망 환경
- 외부 API 사용이 어렵고
- 데이터가 민감하며
- GPU 한 장 수준의 제약이 있는 환경
이때 “작은 모델 + 강한 오케스트레이션”은 꽤 매력적인 선택입니다.
반대로 한계도 분명하다
이 접근을 너무 낙관적으로 보면 안 되는 이유도 있습니다.
첫째, 원문 수치들은 작성자 실험 기준입니다.
공개된 대규모 표준 벤치마크 비교라기보다, 특정 환경에서의 아키텍처 개선 사례로 보는 게 맞습니다. (DEV Community)
둘째, 작은 모델의 한계가 사라진 건 아닙니다.
복잡한 추론, 애매한 지시 해석, 긴 코드베이스의 전역 이해, 새로운 도메인 일반화에서는 여전히 상위 모델이 유리합니다. 이 글의 핵심은 “작은 모델도 최고다”가 아니라, 작은 모델이 실무에서 쓸 만해지는 조건을 보여준다는 데 있습니다. (DEV Community)
셋째, 일부 최적화는 인프라 의존적입니다.
대표적으로 KV 캐시 포킹은 특정 백엔드가 없으면 효과가 제한적입니다. (DEV Community)
실무적으로 가져갈 만한 설계 원칙
이 글을 읽고 바로 적용할 수 있는 핵심만 뽑으면 다음 네 가지입니다.
1. 모델을 바꾸기 전에 출력 형식을 먼저 바꿔라
자유형 문장 대신 표, JSON, 체크리스트, 슬롯 기반 응답을 쓰면 작은 모델이 훨씬 안정적입니다. (DEV Community)
2. 툴 결과는 “증거”만 남기고 압축하라
전체 로그를 넣지 말고, 다음 결정을 위한 신호만 남겨야 합니다. (DEV Community)
3. 에이전트에는 종료 규칙이 필요하다
언제까지 탐색하고 언제 산출로 넘어갈지 시스템이 결정해야 합니다. (DEV Community)
4. 실행 결과는 반드시 검증하라
작은 모델은 말보다 상태 변화 검증이 중요합니다. (DEV Community)
마무리
이 사례가 흥미로운 이유는 “9B도 된다”가 아니라,
에이전트 성능의 상당 부분이 모델 자체보다 아키텍처 설계에서 나온다는 점을 아주 직관적으로 보여주기 때문입니다. (DEV Community)
비싼 API를 붙이지 않아도,
거대한 모델을 쓰지 않아도,
작은 로컬 모델은 다음 조건이 갖춰지면 꽤 쓸 만해집니다.
- 출력 형식을 강하게 구조화하고
- 툴 출력을 압축하고
- 단계를 명확히 끊고
- 메모리를 외부화하고
- 쓰기 결과를 검증하는 것
결국 작은 모델을 에이전트로 만드는 비결은
모델에게 더 많은 자유를 주는 것이 아니라,
올바른 순간에 올바른 선택지만 남겨주는 것입니다. (DEV Community)
'AI' 카테고리의 다른 글
| LangGraph와 Claude Code가 바꾸는 개발 방식 (0) | 2026.04.07 |
|---|---|
| RTK: AI 코딩 에이전트의 토큰 낭비를 줄이는 가장 현실적인 방법 (0) | 2026.04.07 |
| Trellis: 여러 AI 코딩 도구를 하나의 개발 워크플로로 묶는 오픈소스 프레임워크 (0) | 2026.04.07 |
| Harness: 하네스를 프로젝트에 맞게 만들어주는 스킬 (0) | 2026.04.02 |
| Multica: AI 에이전트를 팀원처럼 운영하는 AI 네이티브 프로젝트 관리 도구 (0) | 2026.04.02 |