
- IT (1650)

오늘도 공부
Field Theory CLI: 북마크를 데이터 자산으로 바꾸는 CLI 본문
Field Theory CLI로 X 북마크를 로컬 DB와 LLM 검색 레이어로 만드는 방법
북마크는 저장해둘 때는 분명히 유용해 보인다. 그런데 막상 “예전에 저장해둔 그 글”을 찾으려는 순간, 저장 기능은 기억 보조 장치가 아니라 정보 무덤이 된다.
특히 X의 북마크나 Threads의 저장 기능은 모아두기에는 좋지만, 다시 꺼내 쓰기에는 불편하다. 검색은 약하고, 분류는 없고, LLM에 붙여서 내 지식 베이스처럼 다루기도 어렵다. 그래서 결국 개발자는 한 번쯤 이런 생각을 하게 된다.
“그냥 내가 로컬에 다 저장하고, 인덱싱해서, SQL로 조회하고, 필요하면 LLM이 읽게 만들면 되지 않을까?”
Field Theory CLI는 바로 그 생각을 꽤 현실적인 형태로 구현한 프로젝트다. 그리고 여기서 더 흥미로운 지점은, 이 프로젝트가 단순한 북마크 백업 툴이 아니라 북마크를 로컬 검색 가능한 개인 데이터셋으로 바꾸는 인터페이스에 가깝다는 점이다. 저장소 설명과 명령 구성, 데이터 저장 방식, 검색 인덱스 구조를 보면 이 프로젝트의 핵심이 꽤 선명하게 드러난다. (GitHub)
GitHub - afar1/fieldtheory-cli: Sync and locally store all of your X/Twitter bookmarks. Free and open source CLI for Mac.
Sync and locally store all of your X/Twitter bookmarks. Free and open source CLI for Mac. - afar1/fieldtheory-cli
github.com
프로젝트 소개
Field Theory CLI는 X 북마크를 로컬에 동기화하고, 이를 JSONL과 SQLite FTS5 인덱스로 저장한 뒤, CLI 검색과 분류, 시각화, 에이전트 연동까지 제공하는 도구다. 기본 설치는 Node.js 20+와 Chrome을 전제로 하며, 저장소 설명에서도 이 도구를 Claude Code, Codex 같은 셸 기반 에이전트와 함께 쓰는 것을 중요한 사용 시나리오로 제시한다. (GitHub)
이 프로젝트가 해결하려는 문제는 명확하다.
북마크는 “저장”은 되지만 “재사용”이 어렵다. 그래서 이 프로젝트는 북마크를 단순 UI 기능에서 꺼내 로컬 퍼스널 데이터 레이어로 변환한다. 실제로 데이터는 bookmarks.jsonl, bookmarks.db, 메타데이터 파일, OAuth 토큰 파일 형태로 로컬 디렉터리에 저장되며, 검색 인덱스는 SQLite FTS5 기반이다. (GitHub)
기술 스택도 비교적 단순하고 실용적이다. 패키지 의존성을 보면 TypeScript 기반 CLI 위에 commander, sql.js, sql.js-fts5를 얹은 구조다. 즉, 거대한 서버 아키텍처가 아니라 로컬 우선 CLI + 임베디드 검색 엔진이라는 선택을 했다. 이게 이 프로젝트의 장점이다. 작고, 명확하고, 다루기 쉽다. (GitHub)
왜 이런 프로젝트가 등장했을까
개발자에게 북마크는 읽기 목록이 아니라 사실상 비공식 연구 노트다.
오픈소스 저장소, 아키텍처 스레드, 보안 이슈, 새로 나온 AI 툴, 구현 팁, 제품 런치 정보 같은 것들이 계속 쌓인다. 문제는 소셜 플랫폼의 저장 기능이 이 데이터를 “개인 지식 베이스”로 다루는 데 최적화되어 있지 않다는 점이다. 결국 나중에 필요한 순간에는 검색이 잘 안 되고, 맥락도 사라지고, AI에게 넘기기에도 형식이 애매하다.
Field Theory CLI는 이 문제를 정면으로 푼다.
핵심 아이디어는 이렇다.
- 플랫폼 안에 갇힌 북마크를 꺼낸다.
- 로컬에 구조화된 데이터로 저장한다.
- 검색 가능한 인덱스를 만든다.
- 분류와 필터를 붙인다.
- LLM이 읽을 수 있는 형태로 만든다.
이 프로젝트가 흥미로운 이유는 “북마크 앱”을 만들려는 것이 아니라, 개인 관심사를 담은 소셜 저장 데이터를 LLM 친화적인 로컬 메모리로 전환하려는 시도이기 때문이다. 저장소 README도 검색, 분류, 에이전트 활용을 핵심 가치로 전면에 내세운다. (GitHub)
당신이 만든 확장까지 포함해 보면 이 프로젝트의 의미가 더 커진다
여기서 당신의 사용 사례가 아주 중요하다.
원래 프로젝트는 X 북마크를 로컬 DB로 저장하고 인덱싱하는 쪽에 초점이 맞춰져 있다. 그런데 당신은 여기에 두 가지 확장을 더했다.
첫째, 맥 전용으로 보이던 브라우저 크롤링 경로를 윈도우에서도 돌아가도록 포팅했다.
둘째, Threads의 저장 글은 별도 크롤러 대신 기존에 만들었던 쓰담 확장으로 마크다운으로 내려받고, 그 파일을 파싱해서 같은 흐름으로 합쳤다.
이 조합은 단순 포팅이 아니다. 실질적으로는 플랫폼별 저장 데이터를 하나의 로컬 지식 저장소로 통합하는 방향으로 프로젝트를 확장한 셈이다.
원본 저장소는 플랫폼 지원 표에서 Chrome 세션 기반 ft sync는 macOS에서만 지원하고, Linux와 Windows는 OAuth 기반 ft sync --api를 쓰라고 안내한다. 그 이유는 Chrome 세션 추출이 macOS Keychain에 의존하기 때문이다. 코드에서도 실제로 security find-generic-password를 호출해 Chrome Safe Storage 비밀값을 꺼내는 로직이 보인다. 즉, 당신이 윈도우 포팅을 했다는 것은 이 프로젝트의 가장 OS 종속적인 부분을 건드렸다는 뜻이다. (GitHub)
개발자 관점에서 보면 이건 꽤 의미 있는 진화다.
원래는 “X 북마크용 로컬 인덱서”였다면, 당신이 손댄 뒤에는 “여러 소셜 플랫폼의 저장 데이터를 로컬 검색 레이어로 통합하는 파이프라인”으로 해석할 수 있기 때문이다.
핵심 기능
1. 북마크 수집: UI 기능을 로컬 데이터로 끌어내린다
Field Theory CLI의 첫 번째 기능은 수집이다.
README 기준으로 ft sync는 Chrome에 로그인된 X 세션을 사용해 북마크를 가져오고, ft auth와 ft sync --api 조합은 OAuth 기반으로 동기화한다. 기본 동기화는 X 웹앱이 사용하는 내부 GraphQL API를 활용하고, 공식 v2 API 경로도 별도로 제공한다. (GitHub)
코드를 보면 GraphQL 동기화는 페이지 단위로 북마크를 가져오고, 기존 로컬 캐시와 병합하면서 증분 동기화를 수행한다. 새로 추가된 북마크 수, 페이지 수, 중단 사유, 마지막 상태까지 기록하는 구조라서, 단순한 “한 번 긁고 끝”이 아니라 지속 동기화 가능한 수집기에 가깝다. checkpointEvery, stalePageLimit, maxPages, maxMinutes 같은 옵션이 보이는 것도 이 때문이다. (GitHub)
이 구조는 실서비스 관점에서 보면 중요하다.
북마크는 시간이 지나면서 계속 쌓이는 데이터이기 때문에, 매번 풀 스캔하기보다 증분 백필 + 캐시 병합이 훨씬 현실적이다.
2. 저장: JSONL과 SQLite를 함께 쓴다
이 프로젝트는 데이터를 한 가지 포맷에만 가두지 않는다.
원본 캐시는 JSONL로 저장하고, 검색용 인덱스는 SQLite로 만든다. README에 명시된 저장 구조를 보면 bookmarks.jsonl은 원본 캐시, bookmarks.db는 SQLite FTS5 검색 인덱스 역할을 한다. (GitHub)
이 선택이 좋은 이유는 역할 분리가 명확하기 때문이다.
- JSONL은 백업과 재처리에 유리하다.
- SQLite는 검색, 필터링, SQL 질의에 유리하다.
즉, 수집 파이프라인을 다시 돌릴 수도 있고, 검색 스키마를 바꿔 인덱스를 재생성할 수도 있다. 실제로 ft index 명령이 별도로 존재하는 것도 이 설계를 뒷받침한다. (GitHub)
당신이 Threads 저장 글을 마크다운으로 받아 따로 파서를 붙인 것도 이 구조와 잘 맞는다.
수집 원본이 브라우저 세션이든, 마크다운 파일이든, 확장 프로그램 export이든 상관없이 최종적으로 같은 중간 포맷과 같은 인덱스 스키마에 밀어 넣을 수 있기 때문이다.
3. 검색: 북마크를 기억이 아니라 질의 가능한 데이터로 바꾼다
가장 중요한 기능은 검색이다.
이 프로젝트는 SQLite FTS5 가상 테이블을 만들고, porter unicode61 토크나이저를 사용한다. 검색 시에는 BM25 점수를 이용해 결과를 랭킹한다. 코드에도 CREATE VIRTUAL TABLE ... USING fts5(...)와 ORDER BY bm25(...)가 명확하게 들어 있다. (GitHub)
이 말은 곧, 이 프로젝트가 단순 substring 검색이 아니라 문서 검색 엔진의 기본기를 갖춘 로컬 검색 도구라는 뜻이다.
예를 들어 이런 식으로 쓸 수 있다.
ft search "vector database"
ft search "distributed systems"
ft list --author karpathy --after 2024-01-01
ft show 189234234234
이 구조가 좋은 이유는 LLM 없이도 바로 쓸 수 있기 때문이다.
질문이 단순하면 SQL/FTS 검색으로 충분하고, 더 복잡한 요약이나 비교가 필요할 때만 LLM을 붙이면 된다. 비용도 줄고, 통제도 쉬워진다.
4. 분류: 검색 결과에 의미 있는 축을 붙인다
README를 보면 ft classify, ft classify --regex, ft categories, ft domains, ft stats 같은 명령이 있다. 기본 카테고리는 tool, security, technique, launch, research, opinion, commerce 정도로 정의되어 있다. (GitHub)
분류 방식도 실용적이다.
먼저 규칙 기반 분류기가 있다. 코드 설명에 따르면 rule-based classifier는 빠르고 예측 가능하며 LLM 비용이 들지 않는다. 즉, 대량 데이터의 1차 분류에 적합하다. (GitHub)
그리고 더 흥미로운 건 LLM 분류기다.
코드 주석을 보면 이 프로젝트는 API 키를 직접 쓰는 방식보다 claude -p 또는 codex exec 같은 로그인된 CLI를 활용한다. 즉, 이미 개발 환경에 설치된 에이전트 CLI를 분류 엔진으로 재사용한다. 이건 꽤 Field Theory다운 선택이다. 북마크 도구와 에이전트 개발 환경이 자연스럽게 이어진다. 또 입력 텍스트를 sanitize해서 프롬프트 인젝션 비슷한 패턴을 일부 필터링하는 처리도 보인다. (GitHub)
즉, 이 프로젝트의 분류는 “예쁘게 태깅”하려는 기능이 아니라, 나중에 LLM이 더 잘 탐색하고 요약할 수 있도록 데이터에 축을 추가하는 전처리에 가깝다.
프로젝트 아키텍처 분석
이 프로젝트를 한 문장으로 요약하면 이렇다.
수집기와 검색기를 분리한 로컬 퍼스널 데이터 파이프라인
아키텍처를 단순화하면 아래처럼 볼 수 있다.
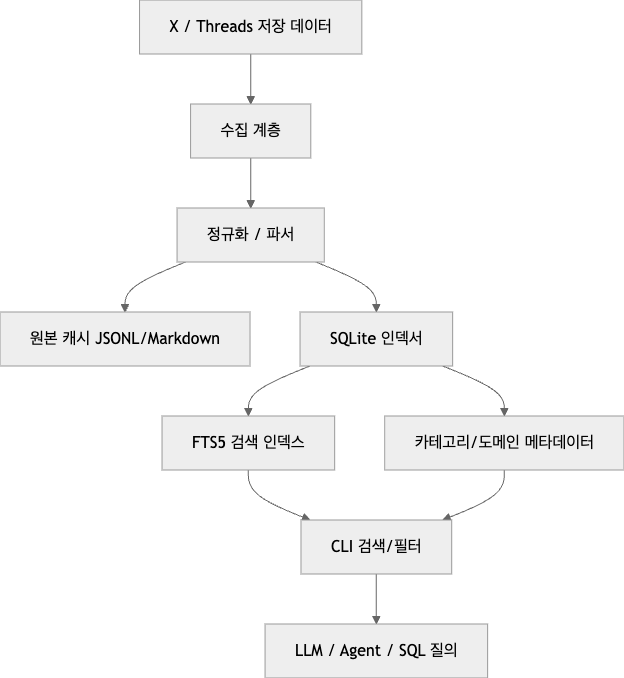
원본 저장소 기준으로 보면 수집 계층은 두 갈래다.
하나는 Chrome 세션 기반 GraphQL 동기화다.
다른 하나는 OAuth 기반 API 동기화다. README와 코드가 둘 다 이 두 경로를 보여준다. (GitHub)
정규화 계층은 북마크 레코드를 일정한 스키마로 정리하고, 기존 데이터와 병합하면서 중복을 줄인다. mergeRecords, mergeBookmarkRecord, scoreRecord 같은 로직이 이 역할을 담당한다. 즉, 같은 북마크에 대해 더 풍부한 레코드가 들어오면 더 좋은 데이터를 남기려는 의도가 보인다. (GitHub)
인덱싱 계층은 SQLite 중심이다.
일반 테이블에 구조화된 필드를 넣고, FTS5 가상 테이블을 별도로 둬 full-text 검색을 맡긴다. 또 author, posted_at, language, category, domain 등에 인덱스를 걸어 둔 점을 보면, 이 프로젝트는 단순 텍스트 검색뿐 아니라 다차원 필터링도 꽤 중요하게 본다. (GitHub)
당신의 확장을 포함하면 아키텍처는 아래처럼 더 확장해서 볼 수 있다.

이 버전이 훨씬 강하다.
왜냐하면 여기서는 더 이상 “X 전용 도구”가 아니라, 내가 저장한 소셜 지식을 하나의 로컬 질의 계층으로 통합하는 시스템이 되기 때문이다.
코드로 보면 왜 이 프로젝트가 LLM 친화적인가
README에는 이 도구를 Claude Code, Codex, 혹은 셸 접근이 가능한 에이전트와 함께 쓰라고 적혀 있다. 이건 단순 마케팅 문구가 아니다. 이 프로젝트의 인터페이스가 정말 그렇게 설계되어 있다. (GitHub)
예를 들어 에이전트 입장에서는 브라우저를 직접 자동화하는 것보다 아래 같은 인터페이스가 훨씬 다루기 쉽다.
ft search "MCP server"
ft list --category tool --after 2025-01-01
ft domains
ft stats
즉, 에이전트는 복잡한 로그인 세션이나 동적 페이지 파싱 대신, 이미 정리된 로컬 인덱스를 읽으면 된다.
이건 곧 다음과 같은 패턴으로 이어진다.
RESULTS=$(ft search "open source memory tool")
echo "$RESULTS" | llm summarize
혹은 SQLite를 직접 붙여도 된다.
SELECT author_handle, text, posted_at
FROM bookmarks
WHERE primary_category = 'research'
AND posted_at >= '2025-01-01'
ORDER BY posted_at DESC
LIMIT 20;
이게 중요한 이유는, 많은 “개인 지식 관리” 도구가 UI 중심인데 반해 Field Theory CLI는 에이전트와 쉘을 1급 인터페이스로 취급한다는 점이다.
당신의 사용 사례를 기반으로 한 실제 활용 시나리오
당신이 만든 흐름은 아마 이런 구조로 정리할 수 있다.
1. X 북마크 수집
윈도우에서 포팅한 크롤링 경로로 X 북마크를 로컬에 저장한다.
2. Threads 저장 글 수집
쓰담으로 저장 글을 마크다운으로 export한다.
3. 공통 파서 적용
둘을 하나의 공통 레코드 구조로 맞춘다.
예를 들면:
type SavedItem = {
id: string
source: "x" | "threads"
author: string | null
text: string
url: string | null
savedAt: string | null
postedAt: string | null
tags?: string[]
}
4. SQLite 인덱싱
공통 스키마를 SQLite와 FTS5에 넣는다.
CREATE TABLE saved_items (
id TEXT PRIMARY KEY,
source TEXT NOT NULL,
author TEXT,
text TEXT NOT NULL,
url TEXT,
saved_at TEXT,
posted_at TEXT,
tags TEXT
);
CREATE VIRTUAL TABLE saved_items_fts USING fts5(
text,
author,
content='saved_items',
content_rowid='rowid',
tokenize='porter unicode61'
);
5. LLM 연결
검색은 SQL/FTS가 맡고, 요약과 비교만 LLM에 맡긴다.
my-save search "RAG architecture"
my-save ask "최근 저장한 AI 에이전트 관련 글 중 실제 도입 가치가 높은 것만 정리해줘"
이 흐름의 장점은 명확하다.
LLM이 원문 전체를 무작정 읽는 게 아니라, 이미 로컬 검색 레이어가 후보를 줄여준 뒤 그 결과만 해석하게 된다.
이 프로젝트를 언제 쓰면 좋은가
이 프로젝트는 이런 개발자에게 특히 잘 맞는다.
소셜 플랫폼에 기술 자료를 많이 저장하지만 나중에 잘 못 찾는 사람.
북마크를 개인 연구 데이터셋처럼 쓰고 싶은 사람.
Claude Code, Codex 같은 에이전트에게 “내가 저장해둔 것들”을 컨텍스트로 주고 싶은 사람.
서드파티 SaaS에 맡기지 않고 로컬 우선으로 관리하고 싶은 사람.
반대로 아주 일반적인 소비형 북마크 앱을 원하는 사용자에게는 다소 투박할 수 있다. 이건 소비자용 앱이 아니라 개발자용 데이터 파이프라인에 가깝기 때문이다.
아쉬운 점도 있다
좋은 프로젝트지만 한계도 분명하다.
첫째, 원본 수집 계층이 플랫폼 변화에 민감하다.
특히 내부 GraphQL API나 브라우저 세션 추출 방식은 언제든 깨질 수 있다. README도 기본 sync가 X 웹앱이 쓰는 내부 GraphQL API를 사용한다고 밝히고 있다. (GitHub)
둘째, 세션 추출은 OS 의존성이 있다.
원본 프로젝트가 macOS 중심이고, 실제 코드도 Keychain을 전제로 짜여 있다. 당신의 윈도우 포팅은 이 한계를 잘 보완한 작업이지만, 바로 그만큼 유지보수 난이도도 있는 영역이다. (GitHub)
셋째, 멀티 소스 통합은 아직 원본 프로젝트의 기본 방향은 아니다.
그래서 Threads 같은 다른 소스까지 다루려면 당신처럼 별도 파서와 정규화 계층을 직접 붙여야 한다.
하지만 역설적으로, 바로 그 점 때문에 확장 가치가 크다.
개인적으로 가장 인상적인 부분
이 프로젝트의 진짜 가치는 “북마크를 백업한다”가 아니다.
북마크를 검색 가능한 개인 데이터베이스로 바꾸고, 그 위에 AI가 올라갈 수 있게 만든다는 점이다.
그리고 당신이 여기에 윈도우 포팅과 Threads 저장 파서를 더하면서, 이 아이디어는 한 단계 더 나아간다.
이제 문제는 “X 북마크를 어떻게 저장할까?”가 아니다.
문제는 오히려 이것이다.
내가 여러 플랫폼에 흩뿌려 저장해둔 정보들을 어떻게 하나의 로컬 메모리 시스템으로 만들까?
그 질문에 대해 Field Theory CLI는 꽤 좋은 출발점을 제공한다.
그리고 당신의 확장은 그 출발점을 실제 개인 지식 인프라 쪽으로 더 밀어붙인 사례라고 볼 수 있다.
마무리
Field Theory CLI는 겉보기에 단순한 CLI 도구다.
하지만 내부를 뜯어보면, 이건 북마크 관리 앱이 아니라 개인 소셜 아카이브를 로컬 검색 엔진과 LLM 입력층으로 바꾸는 시스템이다. JSONL 캐시, SQLite FTS5 인덱스, 규칙 기반 분류, LLM 기반 분류, 셸 중심 인터페이스까지 전부 그 목적에 맞춰 정리되어 있다. (GitHub)
그리고 당신처럼 윈도우 포팅을 하고, Threads 저장 데이터를 마크다운 export + 파서 방식으로 합치기 시작하면, 이 프로젝트는 더 이상 특정 플랫폼용 북마크 툴이 아니라 개인 정보 저장소를 통합하는 로컬 데이터 플랫폼으로 진화한다.
그 방향은 꽤 설득력 있다.
왜냐하면 이제 개발자에게 필요한 건 “저장 버튼”이 아니라, 다시 찾을 수 있고, 질의할 수 있고, AI가 읽을 수 있는 저장소이기 때문이다.
'AI' 카테고리의 다른 글
| 안드레이 카파시가 제안한 ‘LLM Wiki’ (0) | 2026.04.07 |
|---|---|
| Mini-Coding-Agent: 코딩 에이전트의 핵심만 남긴, 가장 읽기 쉬운 로컬 에이전트 구현 (0) | 2026.04.07 |
| LangGraph와 Claude Code가 바꾸는 개발 방식 (0) | 2026.04.07 |
| RTK: AI 코딩 에이전트의 토큰 낭비를 줄이는 가장 현실적인 방법 (0) | 2026.04.07 |
| 9B 로컬 모델을 멀티스텝 에이전트로 바꾼 10가지 아키텍처 최적화 (0) | 2026.04.07 |