
- IT (1682)

Notice
Recent Posts
Recent Comments
반응형
오늘도 공부
LLM Council 아키텍처 본문
반응형
GitHub - karpathy/llm-council: LLM Council works together to answer your hardest questions
LLM Council works together to answer your hardest questions - karpathy/llm-council
github.com
개요
LLM Council은 여러 AI 모델이 협력하여 상호 평가와 종합을 통해 고품질 응답을 생성하는 3단계 심의 시스템입니다.
아키텍처 다이어그램
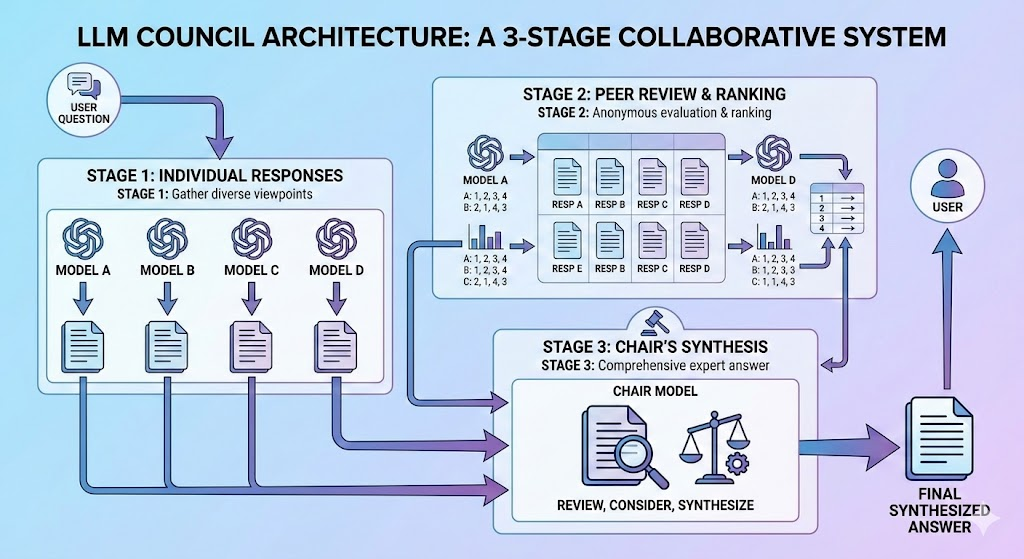
1단계: 개별 응답
목적
동일한 질문에 대해 여러 AI 모델로부터 다양한 관점을 수집합니다.
프로세스
- 사용자 질문이 모든 평의회 모델에 병렬로 전송됩니다 (Rate Limit 처리 포함)
- 각 모델이 독립적으로 응답을 생성합니다
- 응답이 수집되고 저장됩니다
구현 세부사항
- 병렬 실행: Rate Limit을 피하기 위해 모델을 1초 간격으로 순차 호출
- 재시도 로직: 429(Rate Limit) 에러 발생 시 지수 백오프로 자동 재시도
- 타임아웃: 모델당 120초
- 에러 처리: 실패한 응답은 제외하고 성공한 응답으로 진행
현재 평의회 모델
openai-gpt-oss-20b(평균 지연시간 1.82초)llama3.3-70b-instruct(평균 지연시간 1.97초)deepseek-r1-distill-llama-70b(평균 지연시간 1.58초)alibaba-qwen3-32b(평균 지연시간 2.06초)
2단계: 상호 평가
목적
익명화와 구조화된 순위 매기기를 통해 모델들이 서로의 응답을 객관적으로 평가하도록 합니다.
프로세스
- 익명화: 응답에 "응답 A", "응답 B" 등의 라벨을 붙입니다
- 순위 매기기 프롬프트: 각 모델은 다음을 받습니다:
- 원래 사용자 질문
- 모든 익명화된 응답
- 응답을 평가하고 순위를 매기는 지침
- 구조화된 출력: 모델은 다음을 제공해야 합니다:
- 각 응답에 대한 개별 평가
- 특정 형식의 최종 순위:
FINAL RANKING: 1. Response X, 2. Response Y, ...
평가 기준 (암묵적)
모델은 다음 기준으로 평가하도록 지시받습니다:
- 정확성과 올바름
- 깊이와 포괄성
- 명확성과 구조
- 질문과의 관련성
파싱 및 집계
- 정규식 파싱:
FINAL RANKING:섹션에서 순위 추출 - 집계 계산:
- 각 모델의 순위 위치 추적
- 각 모델의 평균 순위 계산
- 낮은 평균 순위 = 더 나은 성능
집계 순위 예시
모델 A: 평균 순위 1.75 (1위 2회, 2위 2회)
모델 B: 평균 순위 2.25 (2위 1회, 3위 3회)
모델 C: 평균 순위 2.50 (1위 1회, 4위 1회, 2위 2회)
모델 D: 평균 순위 3.50 (4위 3회, 3위 1회)3단계: 의장의 종합
목적
모든 정보를 평의회의 집단 지혜를 대표하는 하나의 권위 있는 답변으로 종합합니다.
의장 모델
- 현재:
llama3.3-70b-instruct - 타임아웃: 300초 (큰 컨텍스트로 인해 연장)
입력 컨텍스트
의장은 다음을 받습니다:
- 원래 질문: 사용자의 질문
- 1단계 결과: 모델명과 함께 모든 개별 응답
- 2단계 결과: 근거와 함께 모든 상호 평가 순위
- 집계 순위: 모델 성능의 통계적 요약
종합 전략
의장은 다음을 수행하도록 지시받습니다:
- 개별 응답과 그 통찰력 고려
- 상호 평가 순위와 응답 품질에 대한 시사점 검토
- 합의 또는 불일치 패턴 식별
- 포괄적이고 정확한 최종 답변 종합
품질 요소
- 합의: 여러 모델이 높게 평가한 응답
- 전문성: 높은 집계 순위를 가진 모델의 통찰력
- 다양성: 가치를 더하는 독특한 관점
- 정확성: 상호 검토를 통해 검증된 사실적 정확성
에러 처리 및 복원력
Rate Limiting
- 감지: 429 HTTP 상태 코드
- 재시도 전략: 지터를 포함한 지수 백오프
- 기본 지연: 2초
- 최대 재시도: 5회
- 제공된 경우
Retry-After헤더 준수
- 순차 처리: 모델 호출 사이 1초 지연
실패 시나리오
- 1단계 모든 모델 실패: 사용자에게 에러 메시지 반환
- 1단계 일부 모델 실패: 성공한 응답으로 계속 진행
- 2단계 파싱 실패: 대체 정규식 패턴 사용
- 의장 실패: 1단계 및 2단계 결과가 표시된 에러 메시지 반환
성능 특성
지연시간
- 1단계: ~8-10초 (4개 모델 × ~2초 + 지연)
- 2단계: ~8-10초 (4개 모델 × ~2초 + 지연)
- 3단계: ~5-15초 (컨텍스트 크기에 따라 다름)
- 총합: 쿼리당 ~20-35초
정확도 향상
다단계 접근 방식은 다음을 제공합니다:
- 다양한 관점: 여러 모델이 사각지대를 줄임
- 상호 검증: 교차 확인으로 사실적 정확성 향상
- 종합: 의장이 모든 응답의 최고 통찰력을 결합
API 통합
제공자
- 형식: OpenAI 호환 API
요청 형식
{
"model": "",
"messages": [
{"role": "user", "content": "..."}
]
}향후 개선 사항
잠재적 개선점
- 가중 투표: 역사적 성능이 더 좋은 모델에 더 많은 가중치 부여
- 전문화된 역할: 서로 다른 모델에 특정 평가 기준 할당
- 반복적 개선: 모델이 상호 피드백을 기반으로 응답을 수정할 수 있도록 허용
- 신뢰도 점수: 모델이 응답과 함께 신뢰도 수준 제공
- 도메인 전문성: 특정 도메인에서 입증된 강점을 가진 모델로 질문 라우팅
확장성
- 모델 풀:
COUNCIL_MODELS에서 모델을 쉽게 추가/제거 가능 - 의장 선택: 질문 유형에 따라 동적으로 선택 가능
- 병렬 최적화: Rate Limit이 해결되면 병렬성 증가 가능
반응형
'AI' 카테고리의 다른 글
| Acontext: AI 에이전트를 위한 자기학습 컨텍스트 데이터 플랫폼 (0) | 2025.12.03 |
|---|---|
| Speculators: 표준 기반의 실서비스용 추측 디코딩 솔루션 (0) | 2025.11.23 |
| AI 활용을 위한 30가지 프롬프트 템플릿 완벽 가이드 (0) | 2025.11.11 |
| AI 에이전트는 기억하지 못한다: 시스템으로 지식을 저장하는 법 (0) | 2025.11.10 |
| 프론트엔드 개발자가 오늘 바로 설치해야 할 4가지 MCP (0) | 2025.11.06 |