
- IT (1735)

오늘도 공부
Hermes Agent (스스로 진화하는 에이전트) 본문
Hermes Agent의 핵심은 막연한 “기억하는 AI”가 아니라, 스킬 시스템, 세션 검색, 프롬프트 안정성, 다중 실행 환경, 메시징 게이트웨이, 크론 자동화, RL/trajectory 수집까지 포함한 장기 실행형 에이전트 플랫폼에 더 가깝습니다. 공식 README와 문서에서는 특히 skill_manage를 통한 에이전트 주도 스킬 생성, FTS5 기반 세션 검색, SQLite 기반 세션 저장, 다양한 터미널 백엔드, 메시징 플랫폼 연동, 그리고 연구용 trajectory/data generation을 주요 축으로 설명합니다. (GitHub)
https://github.com/NousResearch/hermes-agent/
hermes-agent/README.md at main · NousResearch/hermes-agent
The agent that grows with you. Contribute to NousResearch/hermes-agent development by creating an account on GitHub.
github.com
Hermes Agent: “기억하는 챗봇”이 아니라, 장기 실행을 전제로 설계된 에이전트 플랫폼
AI 에이전트를 실제로 써보면 금방 드러나는 한계가 있다.
문제를 푸는 능력보다 먼저 부딪히는 건,
**“계속 이어서 일하지 못한다”**는 점이다.
세션이 끝나면 맥락이 끊기고,
복잡한 작업에서 배운 시행착오는 다음 실행에 잘 남지 않는다.
메신저에서 부르든, 터미널에서 부르든, 서버에서 돌리든 같은 에이전트처럼 행동하기도 쉽지 않다.
Hermes Agent는 바로 이 지점을 노린다.
이 프로젝트를 그냥 “기억을 가진 AI 에이전트”라고 부르면 절반만 본 셈이다.
실제로는 스킬을 축적하고, 세션을 검색하고, 여러 플랫폼에서 같은 에이전트로 동작하며, 장기 자동화와 연구용 데이터 생성까지 감안한 운영형 에이전트 시스템에 가깝다. (GitHub)
프로젝트 소개
Hermes Agent는 Nous Research가 공개한 오픈소스 AI 에이전트다. README와 공식 문서는 이 프로젝트를 “self-improving AI agent”로 소개하지만, 실제 구조를 보면 단순한 LLM 래퍼가 아니라 에이전트 런타임 + 툴 실행 계층 + 기억/스킬 계층 + 메시징 게이트웨이 + 스케줄러 + 연구용 데이터 생성 계층을 함께 묶은 형태다. (GitHub)
특히 문서에서 반복해서 강조하는 축은 다음과 같다.
- 에이전트가 스스로 스킬을 만들고 갱신하는 procedural memory
- 세션을 넘어 유지되는 persistent memory
- 과거 대화를 다시 찾는 FTS5 기반 session search
- Telegram, Discord, Slack, WhatsApp, Signal, Email 등으로 이어지는 messaging gateway
- 자연어로 등록하는 cron 기반 자동화
- 로컬, Docker, SSH, Modal, Daytona 같은 다중 실행 환경
- RL/trajectory/synthetic data generation까지 연결되는 research-ready 구조 (GitHub)
즉 Hermes Agent는 “대화형 비서”보다는,
오래 돌릴 수 있고, 여러 인터페이스에서 호출 가능하며, 작업 경험을 시스템적으로 축적하는 에이전트 운영체제처럼 보는 편이 더 정확하다. (hermes-agent.nousresearch.com)
왜 이 프로젝트가 등장했을까
기존 에이전트 프레임워크 다수는 기본적으로 한 세션 안에서만 똑똑하다.
프롬프트를 잘 구성하고, 도구를 연결하고, 필요하면 RAG를 얹는다.
하지만 실제 운영 환경에서는 그보다 더 큰 문제가 남는다.
첫째, 장기 사용성이다.
에이전트가 어제 했던 작업, 지난주에 실패한 방법, 사용자의 선호, 특정 코드베이스의 관습을 일관되게 이어받지 못하면, 장기 협업 도구가 되기 어렵다. Hermes는 persistent memory와 session search, 그리고 user profile/Honcho 같은 계층을 둬서 이 부분을 보완하려 한다. (hermes-agent.nousresearch.com)
둘째, 실행 환경의 분리다.
많은 에이전트가 결국 “내 노트북 터미널에서 돌아가는 도구”에 머문다. 그런데 Hermes는 처음부터 local뿐 아니라 Docker, SSH, Singularity, Modal, Daytona 같은 백엔드를 지원한다. 즉 “어디서 실행할 것인가”를 에이전트 설계의 일부로 본다. 공식 문서가 SSH 백엔드를 보안 측면에서 특히 추천하는 이유도 여기 있다. (hermes-agent.nousresearch.com)
셋째, 플랫폼 일관성이다.
CLI에서만 되는 에이전트와 메신저에서 부를 수 있는 에이전트는 체감상 완전히 다르다. Hermes는 CLI와 messaging gateway를 모두 1급 인터페이스로 취급한다. 그래서 “터미널에서 대화하는 모드”와 “Telegram/Discord에서 같은 에이전트를 부르는 모드”가 별개 기능이 아니라 하나의 아키텍처 위에 놓인다. (GitHub)
넷째, 연구용 활용성이다.
README와 아키텍처 문서는 Hermes를 단순한 사용자용 도구로만 설명하지 않는다. batch trajectory generation, environment framework, Atropos RL integration, training data generation을 함께 언급한다. 즉 실서비스형 에이전트이면서 동시에 차세대 tool-calling 모델을 위한 데이터/환경 수집기로도 쓰려는 의도가 보인다. (GitHub)
Hermes Agent의 핵심은 “기억”보다 “스킬화”에 있다
Hermes를 볼 때 가장 자주 생기는 오해는 이거다.
“아, 메모리 있는 에이전트구나.”
틀린 말은 아니지만, 정확하진 않다.
공식 문서를 보면 memory와 skills는 명확히 분리되어 있다.
memory는 사용자의 환경, 프로젝트, 선호 같은 지속적인 사실 정보를 담는 저장소다. 반면 skills는 에이전트가 작업 과정에서 발견한 재사용 가능한 절차적 지식이다. 문서에서도 skills를 procedural memory라고 부른다. (hermes-agent.nousresearch.com)
예를 들어 memory에는 이런 정보가 들어간다.
- 사용자의 프로젝트 경로
- 이 머신에 설치된 도구
- 응답 스타일 선호
- 현재 작업 중인 서비스의 기술 스택 (hermes-agent.nousresearch.com)
반면 skill은 이런 종류다.
- 특정 저장소에서 릴리스 노트를 만드는 절차
- PDF를 읽고 필요한 내용을 추출하는 반복 가능한 워크플로
- 특정 배포 환경에서 로그를 모으고 문제를 진단하는 단계적 방법
- 어떤 외부 CLI/API를 다루는 요령을 정리한 실행 절차 (hermes-agent.nousresearch.com)
즉 Hermes는 “정보를 저장하는 에이전트”라기보다,
작업 경험을 운영 가능한 절차로 굳히는 에이전트에 더 가깝다.
Memory 시스템은 생각보다 보수적으로 설계되어 있다
공식 memory 문서에서 흥미로운 부분은, 메모리가 단순히 실시간으로 프롬프트에 덕지덕지 붙는 구조가 아니라는 점이다.
세션이 시작될 때 memory가 디스크에서 읽혀 system prompt 안에 frozen block 형태로 주입되고, 그 세션이 진행되는 동안 메모리가 새로 추가되더라도 이미 잡힌 프롬프트 블록은 중간에 바뀌지 않는다. 문서에서는 이걸 prefix cache 보존을 위한 의도적 설계라고 설명한다. 변경 내용은 디스크에는 즉시 저장되지만, 다음 세션이 시작될 때 다시 프롬프트에 반영된다. (hermes-agent.nousresearch.com)
이 설계는 꽤 중요하다.
많은 에이전트는 기억을 많이 넣을수록 좋아질 것처럼 보이지만, 실제로는 프롬프트가 계속 흔들리면 캐시 효율이 떨어지고 모델 동작의 안정성도 나빠질 수 있다. Hermes는 여기서 “항상 최신 메모리를 즉시 반영”하는 대신, 프롬프트 안정성과 지속 저장 사이에서 현실적인 타협을 택했다. 아키텍처 문서에서도 이 프로젝트의 설계 테마 중 하나로 prompt stability를 명시한다. (hermes-agent.nousresearch.com)
이건 단순히 기억 기능이 아니라,
장기 실행 에이전트에서 성능과 비용을 같이 고려한 프롬프트 운영 전략으로 보는 편이 좋다.
Session Search는 “벡터 DB 마법”보다 운영적인 선택에 가깝다
README는 cross-session recall을 위해 FTS5 session search with LLM summarization을 강조한다. 이 표현이 시사하는 건 Hermes가 모든 걸 거대한 의미 검색 시스템으로 밀어넣는 대신, 적어도 세션 검색 영역에서는 SQLite FTS5 같은 실용적인 텍스트 검색과 요약 조합을 택했다는 점이다. (GitHub)
이 접근이 좋은 이유는 분명하다.
장기 사용 에이전트에서 중요한 건 “의미적으로 그럴듯한 관련성”만이 아니다.
오히려 다음이 더 중요할 때가 많다.
- 지난번 정확히 어떤 커맨드를 쳤는지
- 어떤 실패 로그가 있었는지
- 어떤 결정을 했는지
- 어느 날 어떤 서버에서 작업했는지
이런 정보는 종종 정확한 텍스트/기록 검색이 더 유리하다.
Hermes의 session search는 바로 이런 운영형 기억을 겨냥한 선택으로 읽힌다. README의 설명대로 검색 결과를 LLM이 요약해 cross-session recall에 쓰는 방식이라면, 검색 정확도와 LLM 활용을 적당히 분리한 셈이다. (GitHub)
Skill 시스템은 Hermes를 차별화하는 가장 실전적인 장치다
Hermes 문서에서 가장 재미있는 부분은 skill_manage다.
에이전트는 이 도구를 통해 스스로 skill을 create, update, delete할 수 있다.
그리고 문서에는 skill을 언제 생성하는지가 꽤 구체적으로 적혀 있다.
- 5개 이상의 tool call이 들어간 복잡한 작업을 성공했을 때
- 막혔다가 우회 경로를 찾아 해결했을 때
- 사용자가 접근 방식을 교정해줬을 때
- 비사소한 워크플로를 발견했을 때 (hermes-agent.nousresearch.com)
이건 꽤 중요한 신호다.
즉 Hermes는 모든 작업을 무조건 기억하려는 게 아니라,
“반복 가치가 있는 절차”만 skill로 승격시키는 방향을 갖고 있다.
예를 들어 이런 흐름을 상상할 수 있다.
def handle_release_issue(repo):
inspect_tags(repo)
compare_commits(repo)
generate_release_notes()
validate_markdown()
publish_draft()
한 번은 그냥 작업으로 끝날 수 있다.
하지만 Hermes는 이 과정에서 시행착오와 검증 단계를 포함한 절차가 충분히 유의미하다고 판단하면, 이를 skill 형태로 저장해 이후 비슷한 작업에서 재사용하려는 것이다. (hermes-agent.nousresearch.com)
더 흥미로운 점은, 개발자 문서에서 새 capability를 추가할 때 tool보다 skill을 우선 고려하라고 말한다는 것이다. 문서상 기준은 명확하다.
- 기존 툴과 셸 명령 조합으로 표현 가능하면 skill
- 외부 CLI/API를 감싸는 수준이면 skill
- 정교한 Python 통합, 인증 흐름, 실시간 이벤트 처리 등이 필요하면 tool (hermes-agent.nousresearch.com)
이 철학은 Hermes가 단순한 “툴 많은 에이전트”가 아니라,
행동을 코드 변경 없이 확장 가능한 시스템이라는 점을 보여준다.
아키텍처를 보면, Hermes는 “하나의 채팅 루프”가 아니다
공식 Architecture 문서는 아주 직접적으로 말한다.
과거의 “OpenAI-compatible chat loop + some tools”라는 멘탈 모델로는 더 이상 Hermes를 설명할 수 없다. (hermes-agent.nousresearch.com)
프로젝트 구조를 보면 이 말이 왜 나오는지 바로 보인다.
- run_agent.py: AIAgent core loop
- cli.py: 인터랙티브 터미널 UI
- model_tools.py: tool discovery/orchestration
- hermes_state.py: SQLite 기반 세션/상태 DB
- gateway/: 메시징 게이트웨이
- cron/: 스케줄러
- honcho_integration/: 사용자 모델링/메모리 통합
- environments/: RL/benchmark 환경
- skills/, optional-skills/: 스킬 계층 (hermes-agent.nousresearch.com)
이걸 그림으로 단순화하면 이런 느낌이다.
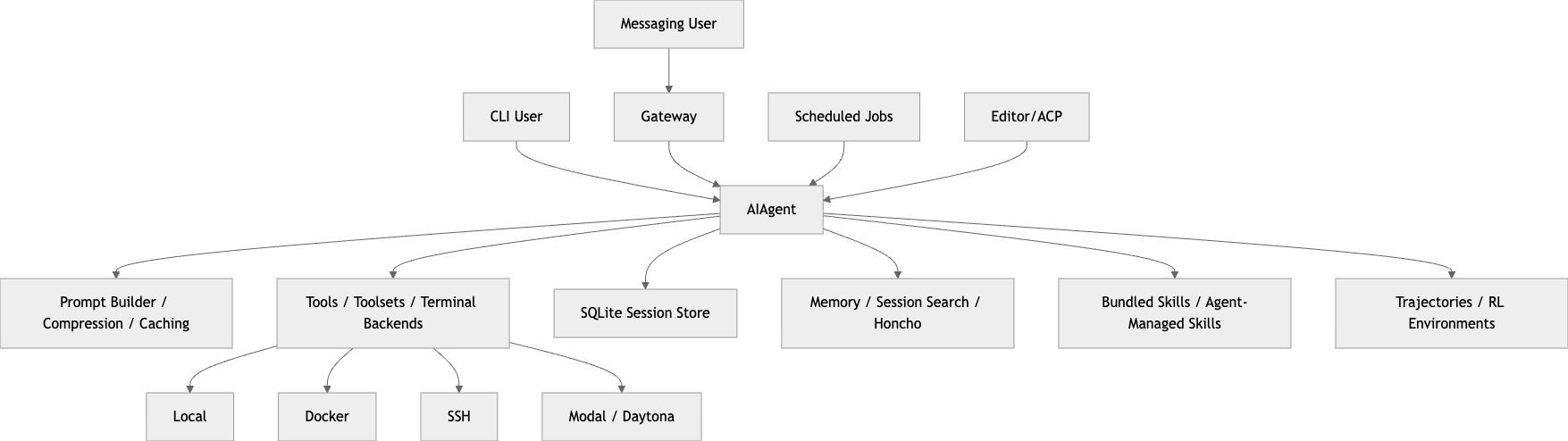
핵심은 입력 채널이 여러 개여도 agent core는 하나라는 점이다.
CLI, 게이트웨이, 크론, ACP 같은 프런트도어가 있고, 아래에는 prompt system, tool runtime, session persistence, memory/skills, research infra가 깔린다. (hermes-agent.nousresearch.com)
그래서 Hermes를 IDE 플러그인처럼 이해하면 안 된다.
오히려 여러 인터페이스를 공통 코어에 연결한 에이전트 런타임이라고 보는 게 맞다.
Tool Runtime은 “툴 호출”보다 “실행 환경 설계”가 더 중요하다
Hermes는 40개 이상의 built-in tool registry를 이야기하지만, 실제로 더 눈에 띄는 건 어떤 툴이 있느냐보다 어디서 그 툴을 실행하느냐다. 공식 tools 문서는 terminal backend를 local, docker, ssh, singularity, modal, daytona로 나눈다. (hermes-agent.nousresearch.com)
이 선택은 실전에서 의미가 크다.
로컬 백엔드는 빠르지만 위험하고,
Docker는 격리와 재현성이 좋고,
SSH는 에이전트를 자기 자신이 있는 머신에서 떼어낼 수 있어 보안상 유리하며,
Modal/Daytona는 서버리스나 원격 지속 환경을 제공한다. 문서에 따르면 container_persistent를 켜면 설치된 패키지와 파일, 설정이 세션을 넘어 유지된다. (hermes-agent.nousresearch.com)
즉 Hermes의 “세션 간 지속성”은 메모리 차원에만 있는 게 아니다.
실행 환경 자체를 지속시킬 수도 있다.
이건 굉장히 큰 차이다.
많은 에이전트가 기억은 저장해도,
실제로 다시 작업할 환경은 매번 초기화된다.
반면 Hermes는 기억 + 환경 + 스킬을 함께 지속 가능한 대상으로 본다. (hermes-agent.nousresearch.com)
Delegation과 Parallelization은 “진짜 멀티 에이전트”를 지향한다
README는 Hermes가 isolated subagents를 spawn해서 parallel workstreams를 처리할 수 있다고 설명한다. 또한 Python scripts that call tools via RPC를 언급하면서, 여러 단계를 하나의 파이프라인으로 접어 넣어 context cost를 줄일 수 있다고 말한다. (GitHub)
이 포인트는 의외로 중요하다.
요즘 많은 프로젝트가 “멀티 에이전트”라고 말하지만, 실상은 프롬프트 안에서 역할놀이만 시키는 경우도 많다. Hermes는 적어도 문서상으로는 격리된 subagent와 실행 파이프라인을 명시적으로 다룬다. 이건 긴 작업을 한 대화 컨텍스트에 계속 쌓아두는 대신, 일부 작업을 분리 실행하고 결과만 회수하는 방향에 가깝다. (GitHub)
운영 관점에서 보면 이 구조는 두 가지 장점이 있다.
하나는 컨텍스트 비용 절감,
다른 하나는 실패 범위 격리다.
긴 작업을 전부 하나의 메인 세션에 밀어 넣지 않기 때문에,
에이전트가 더 오랫동안 안정적으로 돌아갈 수 있다.
보안 모델은 “에이전트니까 위험하다”는 전제를 잘 알고 있다
Hermes의 security 문서는 꽤 구체적이다. 보안 모델을 5개 층으로 정리한다.
- 누가 에이전트와 대화할 수 있는지
- 위험한 명령을 언제 승인받아야 하는지
- 컨테이너 격리
- MCP 자격 증명 필터링
- 프로젝트 파일 내 prompt injection 스캔 (hermes-agent.nousresearch.com)
특히 terminal 사용 시 dangerous command approval이 들어가고, rm -r, mkfs, DROP TABLE, curl ... | sh 같은 패턴은 승인 플로를 타게 되어 있다. 다만 Docker, Singularity, Modal, Daytona 같은 컨테이너 백엔드에서는 컨테이너 자체가 보안 경계라서 이 체크를 건너뛴다고 문서가 명시한다. (hermes-agent.nousresearch.com)
이건 단순한 기능 소개가 아니라, Hermes가 자신을 **“실행 가능한 에이전트”**로 인식하고 설계했다는 뜻이다.
대답만 하는 모델이 아니라, 커맨드를 치고 시스템을 바꾸는 존재이기 때문에 보안 경계를 어디에 둘지 명시해야 한다.
메시징 게이트웨이와 크론이 붙으면서, Hermes는 “항상 켜진 에이전트”가 된다
README에서 개인적으로 가장 실전적이라고 느껴지는 부분은 CLI와 messaging이 동급 인터페이스라는 점, 그리고 cron scheduler가 내장되어 있다는 점이다. Hermes는 CLI로만 쓰는 도구가 아니라, 게이트웨이를 띄우고 Telegram이나 Discord 같은 플랫폼에서 부를 수 있다. 게다가 자연어 기반 스케줄 작업도 지원한다. (GitHub)
이걸 합치면 에이전트 사용 패턴이 바뀐다.
기존에는:
- 필요할 때 로컬에서 실행
- 세션 종료
- 다시 켜면 새 작업 시작
Hermes에서는:
- 원격 환경에서 계속 살아 있음
- 메신저로 호출 가능
- 예약 작업 수행 가능
- 결과를 특정 플랫폼으로 배달 가능 (GitHub)
즉 “코딩할 때 잠깐 쓰는 도구”가 아니라,
백그라운드에서 계속 동작하는 에이전트 프로세스에 가까워진다.
예를 들어 이런 시나리오가 자연스럽다.
hermes gateway setup
hermes gateway start
그리고 메신저에서:
매일 오전 9시에 어제 서버 로그 요약해서 보내줘
이번 주 PR 추세도 금요일에 같이 정리해줘
Hermes를 이해할 때 이 지점이 중요하다.
이 프로젝트의 진짜 경쟁 상대는 단순 챗봇이 아니라, 운영 자동화 스크립트 + 개인 비서 + 원격 에이전트 런타임의 결합체다. (GitHub)
연구 관점에서도 Hermes는 꽤 독특하다
README와 Architecture 문서를 보면 Hermes는 user-facing agent인 동시에 research-ready platform이기도 하다. batch trajectory generation, trajectory compression, RL environments, Atropos integration, next-generation tool-calling models를 위한 데이터 생성이 명시돼 있다. (GitHub)
이건 왜 중요할까?
대부분의 오픈소스 에이전트는
“사용자용 제품”이거나
“연구용 프로토타입” 둘 중 하나로 기운다.
Hermes는 그 둘을 연결하려 한다.
실사용에서 생기는 복잡한 tool trajectory를 모으고,
그걸 압축하고,
환경 프레임워크에서 다시 평가하거나 학습 데이터로 사용할 수 있게 하려는 것이다.
다시 말해 Hermes는 “에이전트를 잘 쓰는 앱”이기도 하지만, 동시에 더 나은 에이전트를 훈련하기 위한 실험장이기도 하다.
언제 Hermes Agent를 쓰면 좋을까
Hermes는 모든 사람에게 맞는 도구는 아니다.
가볍게 API 하나 연결해서 챗봇 만들고 싶다면 너무 크다.
IDE 안에서 자동완성 위주로만 쓰고 싶어도 과하다.
대신 이런 경우에는 상당히 매력적이다.
1. 세션을 넘는 작업 연속성이 중요한 경우
운영, 인프라, 코드베이스 관리, 리서치 같은 작업은 하루 만에 안 끝난다.
이럴 때 memory, session search, persistent environment, skills가 같이 있는 구조가 빛난다. (hermes-agent.nousresearch.com)
2. 터미널과 메신저를 함께 쓰고 싶은 경우
개발은 CLI에서 하고, 상태 확인이나 간단한 지시는 Telegram/Discord에서 하고 싶다면 Hermes의 gateway 모델이 잘 맞는다. (GitHub)
3. 반복 절차를 에이전트가 스스로 정리하길 원하는 경우
일일 보고, 배포 체크, 로그 분석, 문서 생성, 특정 저장소의 반복 작업처럼 절차가 누적되는 영역에서 skill 시스템은 꽤 실용적이다. (hermes-agent.nousresearch.com)
4. 연구와 실사용을 동시에 보고 싶은 경우
trajectory 수집, RL environment, training data generation까지 염두에 둔다면 Hermes는 일반적인 앱형 에이전트보다 훨씬 흥미로운 기반이다. (GitHub)
개발자 관점에서 가장 중요한 해석
Hermes Agent를 한 문장으로 요약하면 이렇다.
Hermes는 “기억하는 챗봇”이 아니라, 오래 실행되며 경험을 스킬화하는 에이전트 런타임이다. (GitHub)
이 프로젝트가 흥미로운 이유는 단순히 메모리가 있어서가 아니다.
- 기억을 facts와 procedural knowledge로 나눈다
- 프롬프트 안정성을 위해 memory 반영 방식을 보수적으로 설계한다
- 텍스트 검색 중심의 session recall을 채택한다
- 실행 환경을 1급 아키텍처 요소로 다룬다
- CLI, 게이트웨이, 크론, ACP를 한 코어 위에 올린다
- 실사용과 연구 데이터를 연결한다 (hermes-agent.nousresearch.com)
그래서 Hermes는 “AI가 쓸수록 똑똑해진다”는 말보다,
**“AI가 쓸수록 더 운영 가능한 형태로 정리된다”**는 표현이 더 정확하다.
그 정리의 단위가 바로 memory, session recall, skill, environment persistence다.
마무리
Hermes Agent는 요즘 흔한 에이전트 데모와 결이 다르다.
한 번 놀라게 하는 자동화보다,
오래 함께 일할 수 있는 구조에 더 집중한다.
그래서 이 프로젝트를 볼 때는 “와, 기억하네?”에서 멈추면 아쉽다.
더 본질적인 질문은 이거다.
에이전트를 진짜 장기 협업 도구로 만들려면 무엇이 필요한가?
Hermes의 답은 꽤 선명하다.
- 기억해야 하고,
- 검색할 수 있어야 하고,
- 스킬로 굳어져야 하며,
- 안전하게 실행돼야 하고,
- 메신저와 터미널을 넘나들어야 하며,
- 필요하면 스스로 일정까지 돌려야 한다.
그 관점에서 Hermes Agent는 단순한 오픈소스 하나가 아니라,
“에이전트를 운영 가능한 소프트웨어로 만드는 방법”에 대한 꽤 구체적인 제안서에 가깝다. (GitHub)
'AI' 카테고리의 다른 글
| Cq: AI 코딩 에이전트를 위한 Stack Overflow (0) | 2026.03.26 |
|---|---|
| Hermes Agent vs OpenClaw 차이점은? (0) | 2026.03.24 |
| MiniMind: 개인 GPU로 LLM을 처음부터 끝까지 이해하게 만드는 가장 작은 풀스택 LLM 프로젝트 (0) | 2026.03.24 |
| PentAGI: 자율형 AI 침투 에이전트 (0) | 2026.03.23 |
| 운영 가능한 Agentic RAG 를 처음부터 제대로 배워보자 (0) | 2026.03.23 |