
- IT (1735)

오늘도 공부
운영 가능한 Agentic RAG 를 처음부터 제대로 배워보자 본문
production-agentic-rag-course: 튜토리얼을 넘어, “운영 가능한 Agentic RAG”를 끝까지 쌓아 올리는 오픈소스
AI 애플리케이션을 만들다 보면 금방 이런 벽을 만납니다.
벡터 DB 하나 붙이고 LLM 호출하면 데모는 되는데, 실제로는 검색 품질이 흔들리고, 데이터 파이프라인은 불안정하고, 관측성은 없고, 에이전트는 왜 그런 답을 냈는지 설명도 못 합니다. jamwithai/production-agentic-rag-course가 흥미로운 이유는 바로 여기 있습니다. 이 저장소는 “RAG를 어떻게 붙이는가”가 아니라, RAG 시스템을 어떻게 운영 가능한 형태로 설계하는가를 7주에 걸쳐 단계적으로 보여줍니다. (GitHub)
이 프로젝트의 결과물은 단순한 예제가 아닙니다. 최종적으로는 arXiv 논문을 수집하고, OpenSearch 기반 검색을 수행하고, 하이브리드 검색과 LLM 응답 생성을 거쳐, LangGraph 기반 Agentic RAG와 Telegram 인터페이스까지 연결되는 연구 논문용 AI 어시스턴트를 만듭니다. 기술 스택도 FastAPI, PostgreSQL, OpenSearch, Airflow, Ollama, Redis, Langfuse, LangGraph로 꽤 현실적입니다. (GitHub)
GitHub - jamwithai/production-agentic-rag-course
Contribute to jamwithai/production-agentic-rag-course development by creating an account on GitHub.
github.com
프로젝트 소개
production-agentic-rag-course는 이름 그대로 “프로덕션 관점의 RAG 구축 과정”을 코드와 노트북으로 풀어낸 학습형 저장소입니다. 저장소 설명에서도 이 프로젝트는 학습자 중심으로 설계된 production-grade RAG 시스템 구축 코스이며, 특히 “처음부터 벡터 검색으로 뛰어들지 않고, 먼저 키워드 검색의 기반을 제대로 다진 뒤 하이브리드 검색으로 확장한다”는 점을 강하게 강조합니다. 이 한 문장만으로도 이 저장소의 철학이 분명합니다. (GitHub)
만든 사람도 중요합니다. 저장소에는 Shirin Khosravi Jam과 Shantanu Ladhwe 두 명의 기여자가 명시되어 있고, README 마지막에도 이 프로젝트가 두 사람이 함께 만든 학습 리소스라고 적혀 있습니다. 즉, 단순 샘플 코드가 아니라 교육용이면서도 구조적으로 실제 시스템에 가깝게 설계된 리포지토리라고 보는 편이 맞습니다. (GitHub)
기술적으로는 Python 3.12를 기준으로 FastAPI, SQLAlchemy, OpenSearch Python client, Docling, Gradio, Langfuse, Redis, python-telegram-bot, LangGraph, LangChain 계열 의존성을 사용합니다. 여기서 핵심은 “RAG 앱” 하나가 아니라, 수집·저장·검색·생성·모니터링·에이전트 오케스트레이션을 한 저장소 안에서 단계적으로 확장한다는 점입니다. (GitHub)
왜 이 프로젝트가 등장했을까
대부분의 RAG 입문 콘텐츠는 “임베딩 → 벡터 검색 → LLM 응답”으로 곧바로 들어갑니다. 문제는 실제 서비스에서 이 접근이 자주 무너진다는 점입니다. 검색 품질은 질문 유형에 따라 달라지고, 인덱싱 전략이 부실하면 임베딩만으로는 성능이 안 나옵니다. 또 운영 단계에선 데이터 적재, 캐싱, 추적, 장애 대응, 재현 가능한 개발 환경이 훨씬 더 중요해집니다. 이 저장소는 README에서 바로 그 문제를 지적하며, 성공적인 회사들은 AI-first가 아니라 search foundation 위에 AI를 얹는다는 메시지를 전면에 둡니다. (GitHub)
그래서 이 프로젝트는 7주 흐름이 매우 의도적입니다.
1주차는 인프라, 2주차는 데이터 파이프라인, 3주차는 BM25 검색, 4주차는 chunking과 hybrid search, 5주차는 완전한 RAG, 6주차는 monitoring과 caching, 7주차는 agentic RAG입니다. 즉, “검색 시스템” 없이 “생성 시스템”을 만들지 않습니다. 이 순서는 단순 학습 편의가 아니라, 운영 환경에서 실패하지 않는 RAG를 만들기 위한 아키텍처 순서에 가깝습니다. (GitHub)
이 저장소가 특별한 이유
1. RAG를 “검색 시스템”으로부터 시작한다
이 프로젝트는 Week 3에서 BM25 기반 OpenSearch 검색을 먼저 구축합니다. 그리고 Week 4에서 chunking과 Jina 임베딩을 도입해 keyword + semantic retrieval을 합친 hybrid search로 확장합니다. 이는 실무적으로 매우 건강한 접근입니다. 검색이 불안정한데 LLM만 바꿔서는 답이 나오지 않기 때문입니다. (GitHub)
2. LLM을 붙이는 순간에도 “대화 UI”보다 “시스템 구조”를 먼저 본다
Week 5에서 Ollama 기반 로컬 LLM과 /api/v1/ask, /api/v1/stream 같은 API를 만들고, 이후에 Gradio UI를 연결합니다. 즉 UI는 본질이 아니라 검증 가능한 API 계층 위에 얹는 인터페이스로 다뤄집니다. gradio_launcher.py도 사실상 src.gradio_app을 띄우는 얇은 진입점일 뿐입니다. (GitHub)
3. 운영 기능이 진짜 포함되어 있다
Week 6에서는 Langfuse tracing과 Redis caching을 넣습니다. 단순히 “답변이 된다”가 아니라, 왜 느린지, 어디서 실패하는지, 같은 질문에 왜 매번 비용이 드는지를 관찰하고 최적화할 수 있게 설계합니다. 실제 compose 파일에도 Redis와 Langfuse 관련 서비스가 함께 정의돼 있습니다. (GitHub)
4. Agentic RAG를 “멋져 보이는 분기”가 아니라 “상태 머신”으로 구현한다
Week 7의 핵심은 LangGraph입니다. README와 release note를 보면 guardrail, document grading, query rewriting, adaptive retrieval, reasoning transparency가 핵심 기능으로 소개됩니다. 실제 agentic_rag.py에서도 StateGraph에 guardrail → retrieve → tool_retrieve → grade_documents → rewrite_query/generate_answer 흐름이 명확하게 구성되어 있습니다. 즉, 이 프로젝트의 agent는 단순한 tool call 모음이 아니라 상태와 라우팅 규칙을 가진 워크플로우입니다. (GitHub)
핵심 기능 분석
인프라 통합
compose.yml을 보면 API, Redis, OpenSearch, OpenSearch Dashboards, Airflow, Ollama, PostgreSQL, ClickHouse, Langfuse worker/web, Langfuse용 Postgres/Redis/MinIO까지 한 번에 띄우도록 구성되어 있습니다. 학습용 저장소인데도 인프라 구성이 꽤 무겁습니다. 그런데 바로 이 점이 장점입니다. 운영형 RAG가 실제로 어떤 서비스 묶음 위에 서는지를 감각적으로 익히게 해줍니다. (GitHub)
하이브리드 검색
환경 변수에서 OPENSEARCH__VECTOR_DIMENSION=1024, OPENSEARCH__RRF_PIPELINE_NAME=hybrid-rrf-pipeline, CHUNKING__SECTION_BASED=true 등이 보입니다. 이걸 보면 이 저장소는 단순한 dense retrieval보다, 문서 chunking + BM25 + 벡터 검색 + RRF 융합을 기본 전략으로 잡고 있습니다. 학술 논문처럼 긴 문서에서는 이 방식이 특히 합리적입니다. (GitHub)
로컬 LLM 중심 설계
환경 변수에는 OLLAMA_MODEL=llama3.2:1b가 기본값으로 들어 있고, compose에서도 Ollama 서비스가 함께 뜹니다. 즉 기본 경험은 외부 SaaS 의존이 아니라 로컬에서 돌아가는 RAG 시스템입니다. 교육용으로도 좋지만, 기업 환경에서 데이터 프라이버시를 고민하는 팀에게도 좋은 출발점입니다. (GitHub)
에이전트의 추론 가시성
AgenticRAGService.ask()는 최종 응답에 answer, sources, reasoning_steps, retrieval_attempts, rewritten_query, guardrail_score 같은 메타데이터를 반환합니다. 이건 꽤 중요한 선택입니다. 많은 에이전트 데모가 내부 과정을 숨기는데, 이 저장소는 반대로 추론 단계를 외부에 노출해 디버깅 가능성을 높입니다. (GitHub)
프로젝트 아키텍처 분석
이 저장소를 하나의 흐름으로 요약하면 아래와 같습니다.
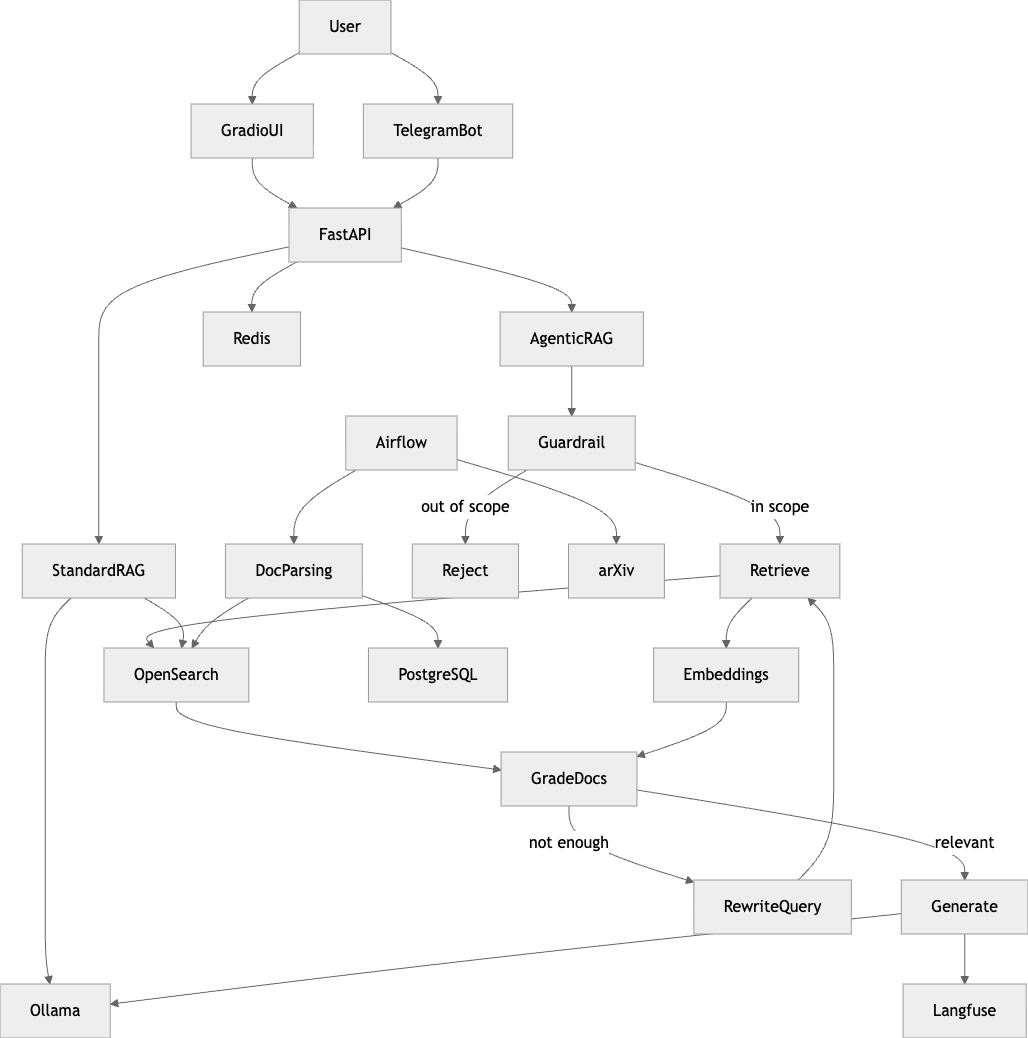
이 아키텍처에서 눈여겨볼 포인트는 세 가지입니다.
첫째, 수집 파이프라인과 질의 파이프라인이 분리되어 있습니다. Airflow는 arXiv 데이터를 가져오고, 파싱 결과는 PostgreSQL과 OpenSearch에 저장됩니다. 둘째, 검색과 생성이 직접 결합되지 않고, 중간에 grading과 rewriting 같은 제어 단계를 둡니다. 셋째, Langfuse와 Redis를 통해 운영 관점의 추적과 최적화를 별도 레이어로 붙입니다. (GitHub)
LangGraph 워크플로우를 코드 관점에서 읽어보자
실제 agentic_rag.py의 핵심은 아래 흐름입니다.
workflow.add_node("guardrail", ainvoke_guardrail_step)
workflow.add_node("out_of_scope", ainvoke_out_of_scope_step)
workflow.add_node("retrieve", ainvoke_retrieve_step)
workflow.add_node("tool_retrieve", ToolNode(tools))
workflow.add_node("grade_documents", ainvoke_grade_documents_step)
workflow.add_node("rewrite_query", ainvoke_rewrite_query_step)
workflow.add_node("generate_answer", ainvoke_generate_answer_step)
workflow.add_edge(START, "guardrail")
workflow.add_conditional_edges(
"guardrail",
continue_after_guardrail,
{
"continue": "retrieve",
"out_of_scope": "out_of_scope",
},
)
workflow.add_conditional_edges(
"retrieve",
tools_condition,
{
"tools": "tool_retrieve",
END: END,
},
)
workflow.add_edge("tool_retrieve", "grade_documents")
workflow.add_conditional_edges(
"grade_documents",
lambda state: state.get("routing_decision", "generate_answer"),
{
"generate_answer": "generate_answer",
"rewrite_query": "rewrite_query",
},
)
workflow.add_edge("rewrite_query", "retrieve")
workflow.add_edge("generate_answer", END)
이 설계가 좋은 이유는 에이전트의 의사결정이 프롬프트 안에 숨어 있지 않다는 점입니다.
가드레일은 범위 밖 질문을 먼저 걸러내고, 검색 결과는 grading을 거친 뒤, 필요하면 query rewrite를 통해 다시 검색합니다. 즉 “생성 이전에 검색 품질을 재평가”합니다. 이것이 일반적인 one-shot RAG와 가장 큰 차이입니다. (GitHub)
API 설계도 꽤 실용적이다
에이전트용 엔드포인트는 /api/v1/ask-agentic입니다. 설명을 보면 이 엔드포인트는 retrieval 필요 여부 판단, 문서 relevance grading, query rewriting, reasoning transparency를 제공합니다. 즉 단순히 답만 주는 API가 아니라, 에이전트 워크플로우의 결과를 구조화된 형태로 반환하는 API입니다. (GitHub)
예를 들면 이런 식으로 호출할 수 있습니다.
import httpx
payload = {
"query": "What are recent methods for improving long-context reasoning in LLMs?",
"top_k": 5,
"use_hybrid": True,
"model": "llama3.2:1b"
}
resp = httpx.post("http://localhost:8000/api/v1/ask-agentic", json=payload)
print(resp.json())
그리고 응답은 이런 형태를 기대할 수 있습니다.
{
"query": "What are recent methods for improving long-context reasoning in LLMs?",
"answer": "...",
"sources": [
{
"title": "Paper A",
"authors": ["..."],
"abstract": "..."
}
],
"reasoning_steps": [
"Validated query scope (score: 91/100)",
"Retrieved documents (1 attempt(s))",
"Graded documents (3 relevant)",
"Generated answer from context"
],
"retrieval_attempts": 1,
"search_mode": "hybrid"
}
개발자 입장에선 이 구조가 매우 좋습니다. 프런트엔드에서 reasoning steps를 그대로 보여줄 수 있고, 운영팀은 retrieval_attempts나 guardrail score를 따로 수집해 품질 분석에 쓸 수 있기 때문입니다. 이 저장소는 에이전트를 UI 레벨이 아니라 API 계약 레벨에서 설계하고 있습니다. (GitHub)
Gradio UI는 왜 붙였을까
src/gradio_app.py를 보면 UI는 http://localhost:8000/api/v1/stream에 붙어 SSE 형태의 스트리밍 응답을 받아옵니다. 사용자는 질의, top_k, hybrid 여부, 모델명, 카테고리 등을 조정할 수 있고, 응답과 함께 search mode, chunks used, source 개수도 확인할 수 있습니다. (GitHub)
이게 의미하는 바는 단순합니다.
이 프로젝트는 “웹 데모”를 만들고 싶은 게 아니라, RAG 엔진을 검증할 수 있는 관찰 가능한 UI를 하나 제공하는 것입니다. UI가 얇아서 더 좋습니다. 핵심 로직이 전부 API에 있으니, 나중에 웹 앱·사내 챗봇·Slack bot·Telegram bot으로 쉽게 갈아탈 수 있습니다. (GitHub)
운영 관점에서 특히 좋은 설계
이 저장소를 실제 서비스 관점에서 높게 평가할 수 있는 부분은 아래 네 가지입니다.
첫째, 환경 변수 설계가 꽤 체계적입니다. .env.example에 OpenSearch, arXiv, PDF parser, chunking, Ollama, Langfuse, Redis, Telegram, Airflow까지 운영에 필요한 설정이 일관되게 드러나 있습니다. 프로젝트를 읽는 것만으로도 어떤 시스템 요소가 필요한지 파악됩니다. (GitHub)
둘째, 관측성과 캐싱을 후순위가 아니라 커리큘럼의 핵심 단계로 둡니다. 많은 튜토리얼에서 monitoring은 빠지지만, 이 저장소는 Week 6 전체를 Langfuse와 Redis에 씁니다. 실무에서는 이게 오히려 더 중요합니다. (GitHub)
셋째, 학습 자료와 코드가 같이 진화합니다. 노트북이 주차별로 존재하고, release도 week1.0부터 week7.0까지 분리되어 있어 특정 시점의 상태를 그대로 재현하기 쉽습니다. 이것은 교육용 저장소에서 생각보다 큰 장점입니다. (GitHub)
넷째, 실전용 도구 체인이 붙어 있습니다. uv, ruff, mypy, pytest, pre-commit까지 들어 있어, “AI 예제”가 아니라 일반 백엔드 프로젝트처럼 다뤄집니다. (GitHub)
이 프로젝트를 언제 쓰면 좋을까
이 저장소는 아래 같은 개발자에게 특히 잘 맞습니다.
RAG를 제대로 배우고 싶은 백엔드 개발자
단순 챗봇이 아니라, 검색 인프라와 API 구조까지 보고 싶다면 아주 좋은 재료입니다. FastAPI, OpenSearch, PostgreSQL, Docker Compose 흐름이 명확합니다. (GitHub)
사내 문서 검색 시스템을 만들 팀
arXiv 대신 사내 PDF, 기술 문서, 정책 문서, 위키를 넣으면 구조는 거의 그대로 재사용할 수 있습니다. 특히 BM25 → hybrid → monitoring → agentic routing으로 가는 순서가 그대로 적용됩니다. 이 평가는 저장소 구조를 기반으로 한 합리적 확장 해석입니다. (GitHub)
“Agentic”을 실전적으로 보고 싶은 엔지니어
이 저장소는 agent를 만능 해결사처럼 포장하지 않습니다. guardrail, grading, rewrite, fallback 같은 제어 가능한 패턴으로 구현합니다. 그래서 화려한 데모보다 훨씬 실용적입니다. (GitHub)
아쉬운 점도 있다
물론 한계도 있습니다.
첫째, compose 스택이 꽤 큽니다. Langfuse용 ClickHouse, 별도 Postgres, MinIO까지 포함되므로 로컬 자원이 부족한 환경에서는 부담이 될 수 있습니다. README도 8GB 이상 RAM과 20GB 이상의 디스크를 권장합니다. (GitHub)
둘째, 학습용 코스 구조라서 “내 서비스에 바로 복붙”하기보다는, 패턴을 가져가서 재조합하는 방식이 더 적합합니다. 특히 arXiv, 논문, 카테고리 전제는 도메인 특화된 부분이기 때문입니다. 이것도 저장소 구조상 자연스러운 해석입니다. (GitHub)
셋째, raw 소스 일부를 보면 GitHub 렌더링상 한 줄로 압축되어 읽히는 파일이 있어 코드 탐독은 약간 불편할 수 있습니다. 다만 README와 릴리스 설명이 잘 되어 있어 전체 구조 파악은 어렵지 않습니다. (GitHub)
한 줄로 정리하면
production-agentic-rag-course는 “RAG 예제 저장소”가 아닙니다.
이 저장소의 진짜 가치는 검색 기반 AI 시스템을 운영 가능한 구조로 키워가는 과정 전체를 보여준다는 데 있습니다. BM25를 먼저 세우고, hybrid search로 확장하고, 로컬 LLM을 붙이고, tracing과 caching을 넣고, 마지막에 LangGraph 기반 agent로 고도화합니다. 이 순서는 매우 실무적이고, 그래서 더 설득력이 있습니다. (GitHub)
개인적으로 이 저장소를 가장 잘 설명하는 문장은 이것입니다.
“Agentic RAG를 배우고 싶다면, 먼저 운영 가능한 RAG가 무엇인지부터 배우게 만드는 저장소.”
바로 그 점 때문에 이 프로젝트는 단순한 튜토리얼보다 훨씬 오래 남습니다. (GitHub)
'AI' 카테고리의 다른 글
| MiniMind: 개인 GPU로 LLM을 처음부터 끝까지 이해하게 만드는 가장 작은 풀스택 LLM 프로젝트 (0) | 2026.03.24 |
|---|---|
| PentAGI: 자율형 AI 침투 에이전트 (0) | 2026.03.23 |
| Claude Code를 ‘제대로’ 쓰는 방법: Garry Tan의 gstack이 보여주는 AI 개발의 새로운 패턴 (0) | 2026.03.23 |
| LightRAG: 벡터 검색만으로 부족한 RAG를 지식 그래프로 보강하는 실전형 프레임워크 (0) | 2026.03.23 |
| ClawFlows: OpenClaw 워크플로우 레이어 (0) | 2026.03.23 |
