
- IT (1663)

오늘도 공부
GuppyLM: 130줄 PyTorch로 끝까지 따라가는 초소형 LLM의 구조 본문
AI를 “잘 쓰는 사람”보다 앞으로 더 강해질 사람은, AI가 왜 그렇게 동작하는지 설명할 수 있는 사람일 가능성이 높습니다.
요즘 대부분의 개발자는 LLM을 API로 호출합니다. 하지만 API 뒤에서 실제로 어떤 일이 벌어지는지, 토크나이저는 왜 필요한지, attention은 어디서 계산되는지, 왜 작은 모델은 금방 문맥을 잃는지까지 손으로 한 번 만들어본 사람은 많지 않습니다. 그래서 지금 Hacker News에서 주목받는 GuppyLM은 단순한 장난감 프로젝트가 아닙니다. 이 프로젝트는 “LLM은 거대한 GPU 클러스터와 미친 자본이 있어야만 이해할 수 있다”는 착각을 정면으로 깨버립니다. 작성자는 이 모델을 약 8.7M 파라미터, 약 130줄짜리 PyTorch 모델 코드, 60K 합성 대화 데이터, 무료 Colab T4에서 약 5분 학습이라는 형태로 공개했고, 실제로 브라우저에서 돌릴 수 있는 데모까지 함께 제공합니다. 현재 GitHub 저장소는 빠르게 주목을 받고 있고, Hacker News에서도 “LLM을 블랙박스처럼 쓰지 말고 직접 만들어보라”는 반응이 이어지고 있습니다. (Hacker News)
https://github.com/arman-bd/guppylm
guppylm/README.md at main · arman-bd/guppylm
A ~9M parameter LLM that talks like a small fish. Contribute to arman-bd/guppylm development by creating an account on GitHub.
github.com
프로젝트 소개
GuppyLM은 “Guppy라는 작은 물고기처럼 말하는” 초소형 언어 모델입니다. 말투는 짧고 소문자 중심이며, 물·먹이·빛·수조 같은 세계만 이해합니다. 반대로 돈, 정치, 스마트폰, 인터넷 같은 인간 추상 개념은 잘 이해하지 못하도록 설계되어 있습니다. 이 덕분에 모델의 목표가 아주 선명해집니다. “범용 지능”을 만들려는 것이 아니라, 작은 Transformer가 어떻게 character behavior를 학습하는지 보여주는 교육용 LLM인 셈입니다. (GitHub)
이 프로젝트를 만든 주체는 GitHub의 arman-bd이며, Hugging Face에도 동일한 이름으로 데이터셋과 사전학습 모델을 공개해두었습니다. 저장소 구조를 보면 단순한 데모를 넘어서, 데이터 생성기, 토크나이저 학습, 학습 루프, 로컬 채팅, 브라우저 실행, ONNX export까지 하나의 미니 LLM 파이프라인으로 묶여 있습니다. (GitHub)
기술 스택도 의도적으로 단순합니다. 핵심 의존성은 PyTorch, Hugging Face tokenizers, datasets, numpy, tqdm 정도입니다. 즉, “현대적인 LLM 시스템의 최소 구성”을 과하게 추상화하지 않고 드러내는 데 초점이 맞춰져 있습니다. (GitHub)
왜 이런 프로젝트가 지금 중요할까
LLM 생태계는 점점 더 거대해지고 있습니다. 수십억~수천억 파라미터, 복잡한 아키텍처, 여러 단계의 정렬, 분산 학습, 추론 최적화가 기본이 되어가죠. 문제는 이 흐름 속에서 많은 개발자가 “사용법”은 익히지만, “구조”는 이해하지 못한 채 도구를 소비하게 된다는 점입니다.
GuppyLM이 흥미로운 이유는 여기에 있습니다. 이 프로젝트는 최신 SOTA를 노리지 않습니다. 대신 “Transformer의 최소 핵심”만 남깁니다. README에서 아예 GQA도 없고, RoPE도 없고, SwiGLU도 없고, early exit도 없다고 선언합니다. 말 그대로 vanilla transformer입니다. 덕분에 개발자는 최신 논문 테크닉의 숲에 들어가기 전에, 언어 모델의 뼈대를 먼저 이해할 수 있습니다. (GitHub)
창업가나 제품 개발자 관점에서도 의미가 있습니다. 지금 AI 제품 경쟁력은 단순히 모델을 호출하는 데서 끝나지 않습니다. 작은 모델이 어디까지 가능한지, 데이터 품질이 행동을 얼마나 결정하는지, 프롬프트가 아니라 가중치에 성격을 심는 방식이 언제 유효한지 이해하는 팀이 훨씬 빠르게 실험합니다. GuppyLM은 바로 그 감각을 익히게 해주는 프로젝트입니다. 이 평가는 제가 저장소 구조와 설계 의도를 바탕으로 내린 해석입니다. (GitHub)
핵심은 “작은 모델”이 아니라 “전체 파이프라인이 보인다”는 점
이 프로젝트를 보면, LLM이 사실 몇 개의 단계로 압축된다는 것을 알 수 있습니다.
- 대화 데이터를 만든다.
- 토크나이저를 학습한다.
- causal language model을 학습한다.
- 샘플링으로 답변을 생성한다.
- 필요하면 ONNX로 내보내 브라우저에서도 돌린다.
이 다섯 단계를 저장소 하나에서 끝까지 볼 수 있습니다. README도 이 점을 명확히 말합니다. “데이터 생성, 토크나이저, 모델 구조, 학습 루프, 추론”을 한 번에 이해하게 해주는 것이 목적이라고요. (GitHub)
아키텍처 분석: 정말로 단순한 Transformer다
GuppyLM의 아키텍처는 다음과 같습니다.
- 파라미터 수: 약 8.7M
- 레이어 수: 6
- hidden dimension: 384
- attention heads: 6
- FFN hidden: 768
- vocabulary size: 4,096
- max sequence length: 128
- positional embedding: learned embedding
- normalization: LayerNorm
- LM head: token embedding과 weight tying (GitHub)
이 수치는 GPT류 모델의 축소판처럼 보이지만, 교육용으로는 꽤 적절합니다. 6개 블록이면 residual path와 attention/FFN 반복 구조를 체감하기 충분하고, 384 차원과 6 heads 조합은 attention tensor shape를 머릿속으로 따라가기에도 부담이 적습니다. 반면 128 토큰 컨텍스트 제한은 분명한 약점이지만, 오히려 왜 작은 모델이 multi-turn 대화에서 금방 무너지는지를 체험하게 만듭니다. README도 실제로 3~4턴 이후 멀티턴 품질 저하 때문에 single-turn 중심 설계를 택했다고 설명합니다. (GitHub)
아래 다이어그램으로 보면 구조는 더 단순합니다.
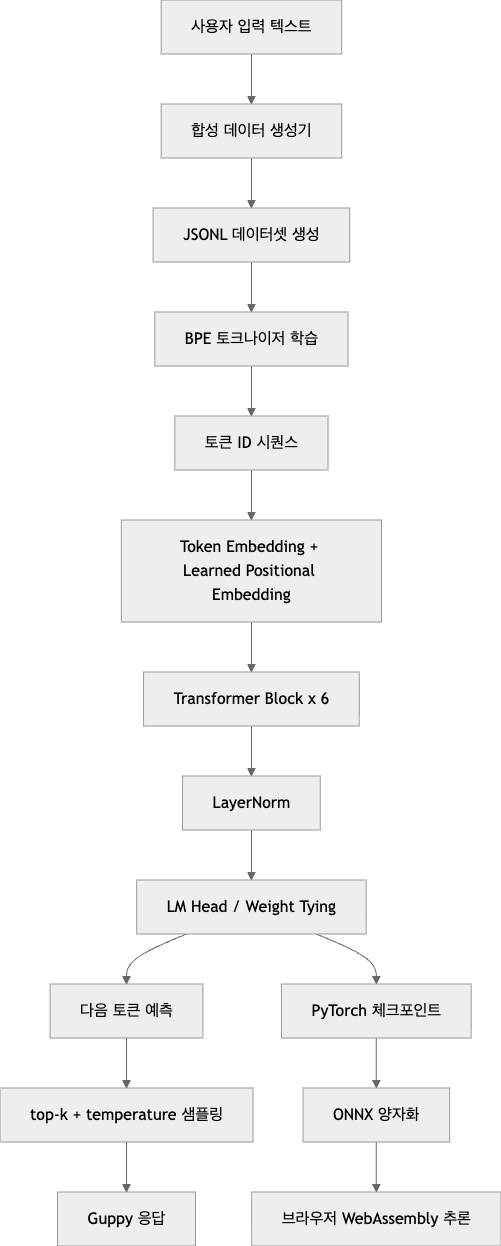
모델 코드도 놀랄 만큼 직설적입니다. Attention에서 qkv를 한 번에 projection하고, causal mask를 torch.tril로 만들고, softmax 후 value를 합칩니다. 그 다음 Block에서 pre-norm residual 구조로 attn과 ffn을 통과시키고, 마지막에 lm_head로 vocabulary logits를 냅니다. 생성은 temperature와 top_k 샘플링만 사용합니다. 정말 교과서적인 causal decoder 구현입니다. (GitHub)
핵심 부분을 요약하면 거의 이런 형태입니다.
class Block(nn.Module):
def __init__(self, config):
super().__init__()
self.norm1 = nn.LayerNorm(config.d_model)
self.attn = Attention(config)
self.norm2 = nn.LayerNorm(config.d_model)
self.ffn = FFN(config)
def forward(self, x, mask=None):
x = x + self.attn(self.norm1(x), mask)
x = x + self.ffn(self.norm2(x))
return x
이 코드는 특별한 최적화 없이도 Transformer의 본질이 무엇인지 정확히 드러냅니다. “언어 모델은 결국 embedding → masked self-attention → feed-forward → next token prediction의 반복”이라는 사실을 추상화 없이 보여주기 때문입니다. 이 코드는 저장소 구조를 바탕으로 제가 가독성 있게 재구성한 예시입니다. 원본 구현의 핵심은 동일합니다. (GitHub)
데이터셋이 이 프로젝트의 진짜 주인공이다
많은 사람이 “130줄 PyTorch”에 먼저 눈길을 줍니다. 하지만 이 프로젝트를 제대로 이해하려면 모델보다 데이터 생성 방식을 봐야 합니다.
GuppyLM은 60,000개의 single-turn 대화를 사용하며, Hugging Face 데이터셋 기준으로 train 57K / test 3K로 나뉘어 있습니다. 데이터 형식은 input, output, category를 가지는 구조입니다. 카테고리는 60개이며, greeting, feeling, food, temperature, weather, meaning_of_life 같은 주제가 포함됩니다. (GitHub)
여기서 중요한 점은 이 데이터가 웹에서 긁어온 자연어 말뭉치가 아니라, synthetic template composition으로 생성된다는 것입니다. generate_data.py를 보면 수조 안 사물, 먹이 종류, 수온 묘사, 활동 패턴, 감정, 빛 상태, 소리 같은 vocabulary pool을 만들어두고, 템플릿에 랜덤하게 조합해 문장을 만듭니다. README는 약 60개 템플릿과 여러 랜덤 조합을 통해 약 16K 고유 출력 패턴이 나온다고 설명합니다. (GitHub)
이게 왜 중요할까요?
작은 모델일수록 “세계지식”보다 “스타일 일관성”이 더 중요합니다. 9M 파라미터 모델에게 범용 상식을 학습시키는 것은 무리지만, “나는 물고기고, 물·먹이·빛 중심으로 세상을 본다”는 좁은 행동 규칙은 충분히 학습시킬 수 있습니다. 즉, GuppyLM은 작은 모델의 약점을 피하고 강점을 살리는 방향으로 데이터 설계를 한 것입니다.
이 전략은 초소형 모델을 캐릭터 봇, 장난감 NPC, 교육용 챗봇, 로컬 인터랙티브 에이전트에 붙일 때 꽤 실용적입니다. 범용 assistant를 만들 생각을 버리고, 좁은 persona와 도메인으로 압축하면 작은 모델도 제법 그럴듯한 결과를 냅니다. 이 부분은 저장소 설계를 바탕으로 한 실무적 해석입니다. (GitHub)
토크나이저도 직접 만든다
prepare_data.py는 데이터 생성 후, 그 텍스트 전체를 다시 읽어와 BPE 토크나이저를 직접 학습합니다. vocabulary 크기는 4,096이고, special token으로 pad / start / end 성격의 토큰을 둡니다. pre-tokenizer와 decoder는 byte-level 구성을 사용합니다. (GitHub)
이 단계가 교육적으로 아주 좋습니다. 실제 LLM을 이해하려면 “텍스트는 그냥 문자열이 아니라 토큰 ID 시퀀스”라는 감각이 먼저 와야 합니다. GuppyLM은 외부 tokenizer를 가져다 쓰지 않고 이 과정까지 보여주기 때문에, 개발자는 다음 사실을 자연스럽게 체험하게 됩니다.
- vocabulary 설계가 모델 크기와 직접 연결된다
- tokenizer가 달라지면 시퀀스 길이와 학습 효율도 달라진다
- 작은 모델은 tokenizer 선택의 영향을 더 크게 받는다
즉, “모델만 보면 LLM을 이해한 것”이 아니라는 점을 이 프로젝트가 잘 보여줍니다. (GitHub)
학습 루프도 딱 필요한 만큼만 있다
train.py 역시 과장 없이 깔끔합니다. 옵티마이저는 AdamW이고, 학습률은 warmup 후 cosine decay를 사용합니다. 기본 학습 설정은 batch size 32, learning rate 3e-4, minimum LR 3e-5, warmup 200 steps, max_steps 10,000, weight decay 0.1, gradient clip 1.0입니다. CUDA 환경에서는 AMP도 사용합니다. (GitHub)
이 설정은 요즘 기준으로 놀라울 정도로 평범합니다. 그런데 바로 그 점이 좋습니다. 작은 프로젝트를 볼 때 흔히 “특수한 트릭이 있겠지”라고 생각하지만, GuppyLM은 정반대입니다. 트릭보다 기본기를 보여줍니다.
학습 루프의 성격은 대략 이렇습니다.
for x, y in train_loader:
lr = get_lr(step, config)
optimizer.zero_grad(set_to_none=True)
logits, loss = model(x, y)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
물론 원본은 AMP, eval loop, checkpoint 저장까지 포함합니다. 하지만 구조 자체는 “다음 토큰 예측 loss를 줄이는 causal LM” 그 자체입니다. 여기서 개발자는 LLM 학습이 생각보다 덜 신비롭다는 것을 느끼게 됩니다. 입력 시퀀스를 한 칸씩 밀어서 x와 y를 만들고, cross entropy를 계산하고, 그걸 반복하면 됩니다. (GitHub)
이 프로젝트가 의도적으로 버린 것들
README의 Design Decisions 섹션은 상당히 정직합니다.
시스템 프롬프트를 쓰지 않은 이유는, 모든 학습 샘플에 같은 persona를 넣어봤자 9M 모델이 instruction-following을 유연하게 해석하기 어렵기 때문입니다. 대신 성격 자체를 가중치에 baked-in 시켰습니다. 또 multi-turn은 128 토큰 문맥 한계 때문에 3~4턴이면 품질이 무너져 single-turn 중심으로 정리했습니다. 그리고 GQA, RoPE, SwiGLU, early exit 같은 현대 기법도 9M 파라미터 수준에서는 복잡도만 늘고 체감 이득이 작다고 보고 제외했습니다. (GitHub)
이 결정들은 꽤 좋은 메시지를 줍니다.
작은 모델은 큰 모델 흉내를 내기보다, 작은 모델에 맞는 제약을 인정해야 합니다.
이 태도는 프로덕트 설계에서도 중요합니다. 작은 모델에게 agentic workflow, 장기 메모리, 범용 reasoning을 다 시키려 하면 대부분 실패합니다. 반대로 좁은 톤, 짧은 응답, 한정된 세계관, 단일턴 상호작용처럼 과업을 잘라주면 꽤 괜찮은 사용자 경험이 나옵니다. GuppyLM은 그 사실을 “물고기 캐릭터”라는 귀여운 형태로 보여줍니다. (GitHub)
브라우저에서 돌아간다는 것도 흥미롭다
README에 따르면 브라우저 데모는 WebAssembly 기반으로 동작하고, 양자화된 ONNX 모델은 약 10MB 수준입니다. 저장소 구조에도 docs/index.html, model.onnx, tokenizer.json, 그리고 tools/export_onnx.py가 포함되어 있습니다. 즉, 이 프로젝트는 “학습 가능한 tiny LLM”일 뿐 아니라 “배포 가능한 tiny LLM”이기도 합니다. (GitHub)
이건 꽤 실전적인 포인트입니다. 모든 LLM 제품이 서버 추론이 필요한 것은 아닙니다. 캐릭터 챗, 장난감 UI, 교육용 실습, 브라우저 기반 인터랙션은 오히려 로컬 추론이 더 나을 수 있습니다. 네트워크 지연도 없고, API 비용도 없고, 개인정보 전송 이슈도 줄어듭니다.
물론 GuppyLM이 범용 프로덕션 모델이라는 뜻은 아닙니다. 하지만 “작은 모델을 어디까지 로컬에 밀어 넣을 수 있는가”를 탐색하기에는 아주 좋은 예제입니다. (GitHub)
개발자가 실제로 얻는 학습 포인트
이 프로젝트를 읽으면 다음 질문들에 답할 수 있게 됩니다.
1) LLM은 정말 next-token prediction만으로 동작하나?
그렇습니다. GuppyLM도 본질적으로는 causal LM입니다. 입력 시퀀스의 다음 토큰 분포를 예측하고, 그걸 반복해 문장을 생성합니다. (GitHub)
2) 작은 모델도 persona를 학습할 수 있나?
가능합니다. 단, 범용 지식을 학습시키려 하기보다, 좁고 일관된 말투와 세계관을 데이터에 강하게 주입해야 합니다. GuppyLM의 synthetic data 설계가 바로 그 예입니다. (Hugging Face)
3) 토크나이저를 왜 직접 봐야 하나?
토크나이저는 모델이 세상을 보는 단위입니다. 작은 모델일수록 vocabulary 크기와 토큰 길이의 trade-off가 더 직접적으로 품질에 반영됩니다. GuppyLM은 그 과정을 감추지 않습니다. (GitHub)
4) 왜 긴 문맥과 멀티턴 대화가 어려운가?
max sequence length가 128으로 매우 짧기 때문입니다. 저장소도 이 한계를 숨기지 않고 single-turn 중심 사용을 권장합니다. (GitHub)
직접 바꿔보면 더 재밌는 포인트
이 프로젝트는 사실 “물고기 모델”보다 “캐릭터 LLM 스타터킷”에 가깝습니다. README의 Hacker News 소개에서도 작성자는 “fork해서 자기만의 캐릭터로 바꿔보라”고 말합니다. (Hacker News)
예를 들어 이런 식으로 바꿔볼 수 있습니다.
1) 캐릭터를 바꾸기
generate_data.py의 vocabulary pool과 템플릿을 수정해, 고양이, 로봇, 우주선 정비사, 게임 NPC 같은 캐릭터를 만들 수 있습니다.
ROBOT_OBJECTS = ["servo", "battery pack", "charging dock"]
ROBOT_STATES = ["low power", "stable", "processing"]
def _robot_greeting():
return join_sentences(
"hello, operator.",
f"power state: {pick(ROBOT_STATES)}.",
f"i was checking the {pick(ROBOT_OBJECTS)}."
)
2) 도메인 챗봇으로 줄이기
캐릭터 대신 “사내 배포 도우미”, “CLI 튜터”, “SQL 학습용 봇” 같은 좁은 역할로 바꿀 수 있습니다. 핵심은 세계를 좁히는 것입니다.
3) 문맥 길이와 데이터 다양성의 trade-off 실험하기
max_seq_len, vocab_size, n_layers, d_model을 조금씩 올려보면, 어느 지점에서 무료 Colab 학습 비용과 품질이 갈라지는지 감을 잡을 수 있습니다. GuppyLM의 기본 설정은 이런 실험의 출발점으로 좋습니다. (GitHub)
언제 쓰면 좋고, 언제 쓰면 안 좋을까
GuppyLM은 이런 상황에 잘 맞습니다.
교육용 LLM 실습, tiny transformer 구조 학습, synthetic dataset 실험, 캐릭터 챗봇 프로토타입, 브라우저 내 로컬 추론 데모 같은 경우입니다. 특히 팀 내부에서 “LLM이 정확히 뭔지” 빠르게 공통 이해를 맞추고 싶을 때 아주 좋습니다. 저장소 하나로 tokenizer부터 inference까지 다 보여주기 때문입니다. (GitHub)
반대로 이런 용도에는 맞지 않습니다.
범용 질의응답, 긴 문맥 reasoning, 도구 사용, 멀티턴 assistant, 고품질 factual chatbot, production-grade customer support 같은 용도입니다. 모델 크기와 문맥 길이, 데이터 설계가 애초에 그 목적을 향하지 않습니다. README도 이를 숨기지 않습니다. (GitHub)
한 줄로 요약하면
GuppyLM이 진짜로 보여주는 것은 “9M 파라미터도 대단하다”가 아닙니다.
LLM은 생각보다 이해 가능한 시스템이고, 좋은 데이터와 적절한 제약이 있으면 아주 작은 모델도 꽤 설득력 있는 행동을 만들 수 있다는 사실입니다. 이 프로젝트가 Hacker News에서 반응을 얻는 이유도 여기에 있습니다. 사람들은 더 큰 모델보다, 더 잘 설명되는 모델에 목말라 있습니다. (Hacker News)
개발자에게 GuppyLM은 장난감이 아니라 좋은 출발점입니다. 거대한 모델을 숭배하기 전에, 이런 작은 모델을 직접 뜯어보는 쪽이 훨씬 빠르게 실력을 올려줍니다.
'AI' 카테고리의 다른 글
| RedditVideoMakerBot: Reddit 영상을 한 번의 명령으로 만드는 자동화 도구 (0) | 2026.04.08 |
|---|---|
| SEO Machine: Claude code로 작성하는 SEO 글쓰기 (0) | 2026.04.08 |
| KarpathyTalk: AI와 공존하기 위한 트위터같은 플랫폼 (0) | 2026.04.08 |
| GitNexus: 서버 없이 코드베이스를 이해하는 그래프 기반 코드 인텔리전스 (0) | 2026.04.08 |
| 안드레이 카파시가 제안한 ‘LLM Wiki’ (0) | 2026.04.07 |